DjangoにPythonスクレイピングを実装した簡易検索エンジンの作り方【BeautifulSoup】
- 作成日時:
- 最終更新日時:
- Categories: サーバーサイド
- Tags: django スクレイピング BeautifulSoup 初心者向け

DjangoにPythonスクレイピングを実装させるだけで簡易的な検索エンジンを作ることができる。
しかも、モデルの定義は不要でビューとテンプレートだけなので初心者の演習におすすめ。
流れ
Djangoの環境構築、プロジェクトの作成等は割愛します。
- アプリを作る
- urls.pyを修正
- views.pyを作る
- テンプレートを作る
- スクレイピングのコードを作る
- views.pyを修正
- テンプレートを修正
- 開発サーバーを起動して動作チェック
アプリを作る
python3 manage.py startapp search
urls.pyを修正
プロジェクト直下のurls.pyである、config/urls.pyを修正。下記を追加。
path('', include("search.urls")),
アプリディレクトリ内のurls.pyに当たる、search/urls.pyを作成。
from django.urls import path
from . import views
app_name = "search"
urlpatterns = [
path('', views.index, name="index"),
]
views.pyを作る
search/views.pyに下記を入力。クラスベースのビューを作る。
from django.shortcuts import render
#クラスベースのビューを作るため
from django.views import View
class SearchView(View):
def get(self, request, *args, **kwargs):
return render(request,"search/base.html")
def post(self, request, *args, **kwargs):
pass
index = SearchView.as_view()
今回はpost文は無し、GET文だけで作る。
テンプレートを作る
views.pyから呼び出されているtemplates/search/base.htmlが存在しないので作る。
{% load static %}
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>カスタム検索エンジン</title>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/css/bootstrap.min.css" integrity="sha384-Vkoo8x4CGsO3+Hhxv8T/Q5PaXtkKtu6ug5TOeNV6gBiFeWPGFN9MuhOf23Q9Ifjh" crossorigin="anonymous">
<link rel="stylesheet" href="https://use.fontawesome.com/releases/v5.1.0/css/all.css" integrity="sha384-lKuwvrZot6UHsBSfcMvOkWwlCMgc0TaWr+30HWe3a4ltaBwTZhyTEggF5tJv8tbt" crossorigin="anonymous">
<link rel="stylesheet" href="{% static 'css/style.css' %}">
{% block head %}
{% endblock %}
</head>
<body>
<h1 class="title"><a href="{% url 'search:index' %}">カスタム検索エンジン</a></h1>
<main class="container">
</main>
</body>
</html>
スクレイピングのコードを作る
ここが本記事の要。事前にpipコマンドでrequestsとBeautifulSoupをインストールしておきましょう。
search/scraping.pyとして作る。
import sys,bs4,requests
SEARCH_NUM = "100"
TIMEOUT = 10
HEADER = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:63.0) Gecko/20100101 Firefox/63.0'}
#グーグル検索から検索結果のリストを返す関数
def search_google(words):
link_list = []
title_list = []
try:
url = "https://www.google.co.jp/search?q="+words+"&num="+SEARCH_NUM+"&start=0"
result = requests.get(url, timeout=TIMEOUT, headers=HEADER)
result.raise_for_status()
except Exception as e:
print("ERROR_DOWNLOAD:{}".format(e))
else:
soup = bs4.BeautifulSoup(result.content, 'html.parser')
links = soup.select(".rc > div > a")
titles = soup.select(".rc > div > a > h3 > span")
link_list = [link_tag.get("href") for link_tag in links]
title_list = [title_tag.get_text() for title_tag in titles]
#タイトルとリンクが不一致の場合、
if len(link_list) != len(title_list):
return [],[]
return link_list,title_list
def main():
words = input("検索ワードを入力してください")
print(search_google(words))
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("\nprogram was ended.\n")
sys.exit()
やっていることは、概ねこんな感じ。
- グーグル検索をした上で、検索結果に表示されるHTMLをrequestsでDLする。
- 手に入れたHTMLデータをBeautifulSoupが解析して文字列(検索結果のタイトルとリンク)を入手する。
jQueryのセレクタをやったことがある人はすぐにわかると思う。
注意点として、グーグルの検索結果をスクレイピングする際、ユーザーエージェント未指定だと正常に読み取ることが出来ない(おそらくグーグル側のボット対策?)。それ故、requests.get()の引数としてHEADERを指定している。
views.pyを修正
from django.shortcuts import render
# Create your views here.
#クラスベースのビューを作るため
from django.views import View
#スクレイピングのコードをインポート
from . import scraping
import time
#拒否したいURLのリスト
DENY_URL_LIST = [ "ここに拒否したいURLを入力",
]
DENY_TITLE_LIST = [ "ここに拒否したいサイトタイトルを入力",
]
#Viewを継承してGET文、POST文の関数を作る
class SearchView(View):
def get(self, request, *args, **kwargs):
if "search_word" in request.GET:
if request.GET["search_word"] != "":
start_time = time.time()
word = request.GET["search_word"]
#検索結果を表示
link_list,title_list = scraping.search_google(word)
#テンプレートで扱いやすいように整形
data = []
link_list_length = len(link_list)
#ここで特定URL、タイトルのサイトを除外する。
for i in range(link_list_length):
allow_flag = True
for deny in DENY_URL_LIST:
if deny in link_list[i]:
allow_flag = False
break
if allow_flag:
for deny in DENY_TITLE_LIST:
if deny in title_list[i]:
allow_flag = False
break
if allow_flag:
data.append( { "url":link_list[i] , "title":title_list[i] } )
end_time = int(time.time() - start_time)
context = { "search_word" : word,
"data" : data,
"time" : end_time
}
return render(request,"search/results.html",context)
return render(request,"search/base.html")
def post(self, request, *args, **kwargs):
pass
index = SearchView.as_view()
views.pyはscraping.pyを呼び出し、実行させる。返却されるのは検索結果として表示されるサイトのタイトルとURLのリスト型変数。
そこから拒否したいタイトルとURLをあぶり出し、除外する。
そしてレンダリング。
テンプレートを修正
search/base.htmlを修正
{% load static %}
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>カスタム検索エンジン</title>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/css/bootstrap.min.css" integrity="sha384-Vkoo8x4CGsO3+Hhxv8T/Q5PaXtkKtu6ug5TOeNV6gBiFeWPGFN9MuhOf23Q9Ifjh" crossorigin="anonymous">
<link rel="stylesheet" href="https://use.fontawesome.com/releases/v5.1.0/css/all.css" integrity="sha384-lKuwvrZot6UHsBSfcMvOkWwlCMgc0TaWr+30HWe3a4ltaBwTZhyTEggF5tJv8tbt" crossorigin="anonymous">
<link rel="stylesheet" href="{% static 'css/style.css' %}">
{% block head %}
{% endblock %}
</head>
<body>
<h1 class="title"><a href="{% url 'search:index' %}">カスタム検索エンジン</a></h1>
<main class="container">
<form class="search_area" action="">
<input class="form-control" type="text" name="search_word" autofocus value="{{ search_word }}">
</form>
{% block main %}
{% endblock %}
</main>
</body>
</html>
search/results.htmlを新たに作る
{% extends "search/base.html" %}
{% block main %}
<!--ここに検索結果を表示する-->
{% if data|length != 0 %}
<p>{{ data|length }} 件ヒットしました (所要時間:約 {{ time }} 秒)</p>
{% for content in data %}
<div class="sitelink_area">
<div class="sitelink"><a href="{{ content.url }}">{{ content.title }}</a></div>
<!--truncatechars_htmlで指定文字数で切り詰めできる-->
<div class="url">{{ content.url|truncatechars_html:"100" }}</div>
</div>
{% endfor %}
{% else %}
<p><span class="caution"> {{ search_word }} の検索結果は見つかりませんでした。</span>(所要時間:約 {{ time }} 秒)</p>
{% endif %}
{% endblock %}
検索する場合は、results.htmlを検索しない場合は、base.htmlをそのまま表示させる。
開発サーバーを起動して動作チェック
こんなふうに表示されれば成功。
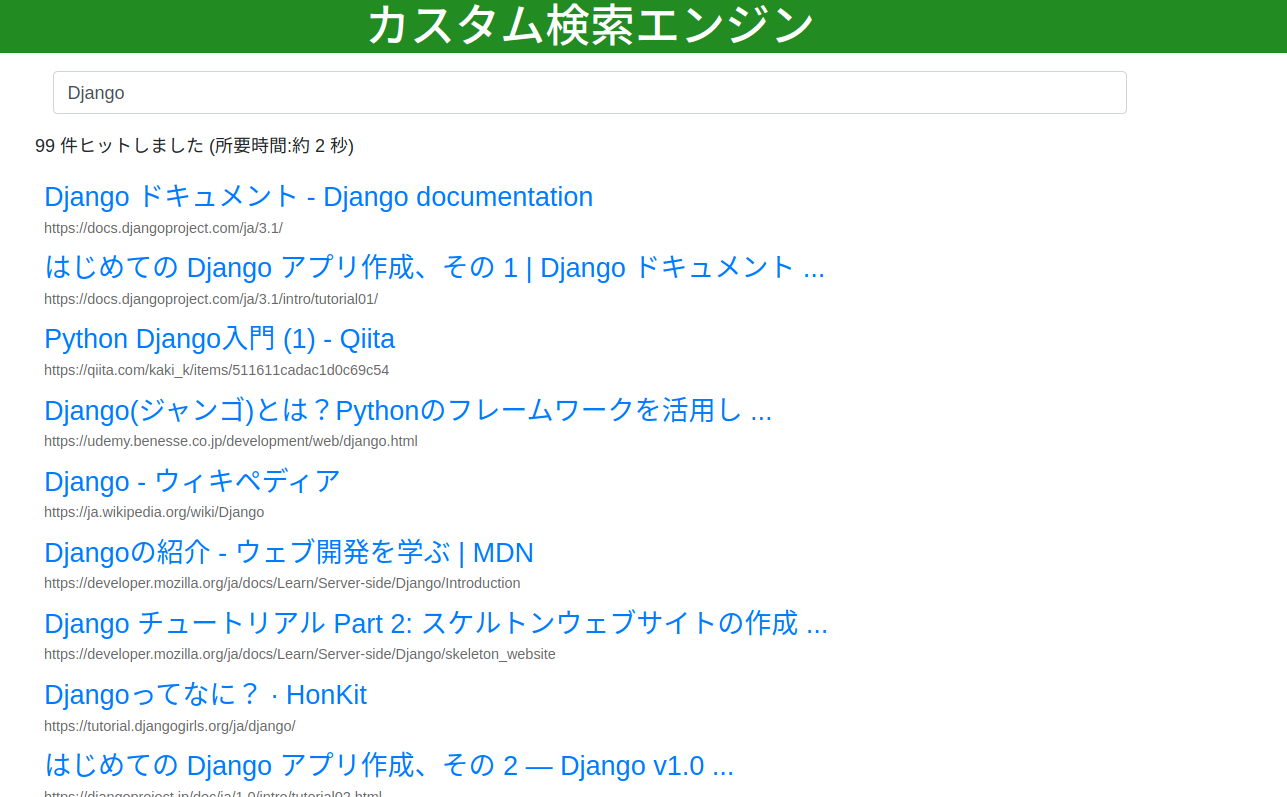
結論
こんな物を作って何になるんだって突っ込まれるかも知れないけど、たまに不適切なウェブサイトが検索結果に表示されることがあるので、そういうのを見たくない人には都合が良いと思う。
それから、再帰的にスクレイピングを行いつつ、なおかつMecabとかの形態素解析ツールを併用すれば、サイト内の文言にも検閲をかけることができる。
さらに、アクセスしたサイトをDBにまとめていけば、自分好みの検索エンジンを作ることができるのではと。
使っている外部のライブラリもrequestsとBeautifulSoupだけなので、Herokuの無料プランでも簡単にデプロイできる。
ただ、スクレイピングのデメリットはスクレイピング対象のサイトの仕様変更のたびに修正を強いられること。抜き取る要素の名前が変わればそのたびにコードを修正しないといけないのは少々面倒だ。