【Ubuntu】tesseractをインストールして、Pythonから画像の文字起こし(OCR)を試す【pytesseract】

環境
- Ubuntu 20.04
- Python 3.8.10
- Tesseract Open Source OCR Engine v4.1.1 with Leptonica
今回使用したPythonライブラリ
packaging==21.3
Pillow==9.2.0
pyparsing==3.0.9
pytesseract==0.3.10
UbuntuへTesseractのインストール
sudo apt install tesseract-ocr libtesseract-dev libleptonica-dev tesseract-ocr-jpn tesseract-ocr-jpn-vert tesseract-ocr-script-jpan tesseract-ocr-script-jpan-vert
日本語のOCRもできるように訓練済みのデータもインストールしている。
tesseract-ocr-jpn tesseract-ocr-jpn-vert tesseract-ocr-script-jpan tesseract-ocr-script-jpan-vert
Tesseractの動作確認
以下画像をdjango.pngと名付けて解析してみる。
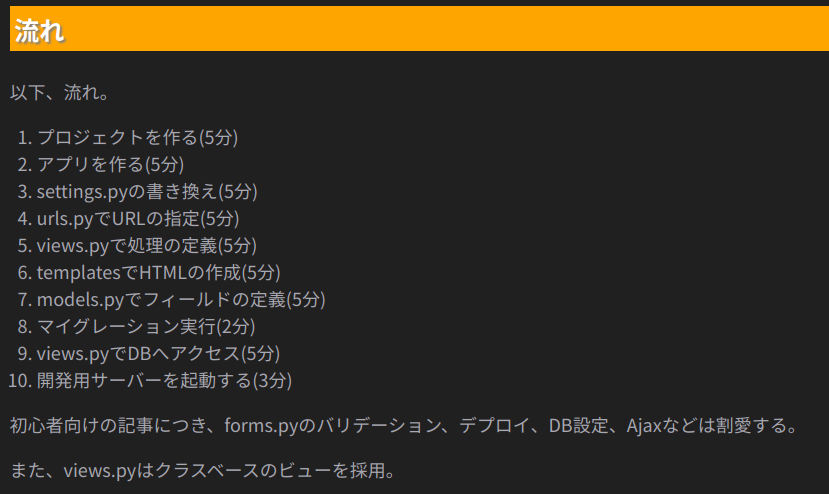
tesseract django.png output -l jpn
ファイルはoutput.txtに出力される。出力結果はこうなった。
以下、流れ。
1. プロジェクトを作る(5分)
2. アプリを作る(5分)
3.settings.pyの書き換え(5分)
4.urls.pyでURLの指定(5分)
5.views.pyで処理の定義(5分)
6.templatesでHTMLの作成(5分)
7.models.pyでフィールドの定義(5分)
8.マイグレーション実行(2分)
9.views.pyでDBヘアクセス(5分)
10. 開発用サーバーを起動する(3分)
初心者向けの記事につき、forms.pyのバリデーション、デプロイ、DB設定、Ajaxなどは割愛する。
また、Vviews.pyはクラスベースのビューを採用。
見出しが取れていなかったり、多少の間違いこそあれ、正常に動作しているようだ。これでUbuntuへのインストールは完了だ。
Pythonから動作させる
pyocrか、pytesseractか?
このtesseractをPythonから動作させるラッパーライブラリとして、pyocrとpytesseractなどがある。
https://tesseract-ocr.github.io/tessdoc/AddOns
現行(2022年10月)のtesseractのバージョンは4.1.1。この4.1.1のtesseractをサポートしているPythonライブラリは以下の通り。

つまり、pyocrはtesseract4.1.1をサポートしていないようだ。
この中でGitHubのスター数が一番多いのは、pytesseractの4.5k。よって、今回はpytesseractを使用するのが妥当と判断した。
pip install pytesseract
pytesseractを使用して、tesseractを動かし、画像のOCRを試す。
とりあえずカレントディレクトリの画像を読み込み、文字を起こす
from PIL import Image
import pytesseract
from pathlib import Path
BASE_DIR = Path(__file__).resolve().parent
FILE_PATH = BASE_DIR / "django.png"
image = Image.open( str(FILE_PATH) )
text = pytesseract.image_to_string(image, lang="jpn")
print(text)
このように出力された。
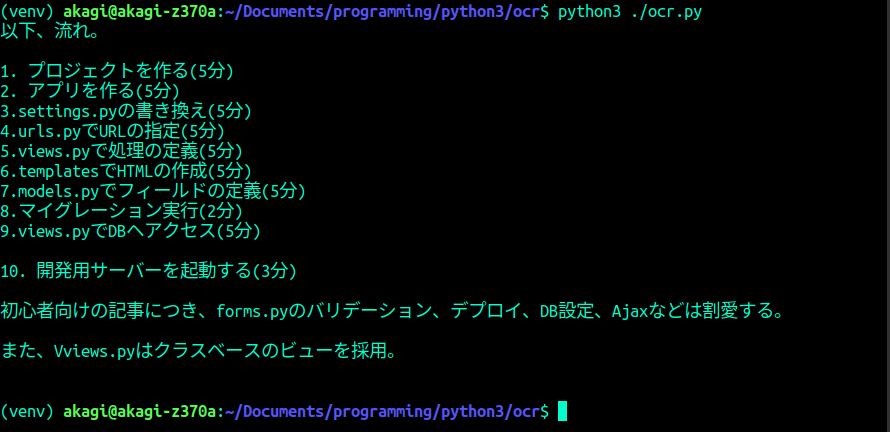
結論
このOCRをDjango上で動作させ、入力作業を大幅に削減するという使い方もあるだろう。
例えば、家計簿系ウェブアプリで、レシートの画像をアップロードし、OCRを発動して、入力作業を減らす。
例えば、画像化されているウェブページのスクリーンショットを撮って、OCRを発動して、より高度なスクレイピングをする。
ただ、別途学習モデルを入れない限り、手書きやカメラで撮影したデータの解析は難しいようだ。
画像を2階調化(モノクロ化)して解析することで少し精度を向上させることもできるが、それでも既存の学習モデルでは限界がある。
現在の学習モデルで満足にOCRが動作してくれるのは、ページのスクリーンショットぐらいと思われる。
ちなみにtesseractに学習モデルを追加する方法は下記サイトに書かれてある。