DjangoでDBに格納したデータをダンプ(バックアップ)させる【dumpdata】

以前、Djangoで開発中に初期データを入力する方法をしたが、Djangoではその逆も可能。
つまり、DBに既に格納されているデータをダンプ(バックアップ)する事ができる。それがこれ
python3 manage.py dumpdata [アプリ名] > [アプリ名]/fixture/data.json
実際にやってみるとこうなる。

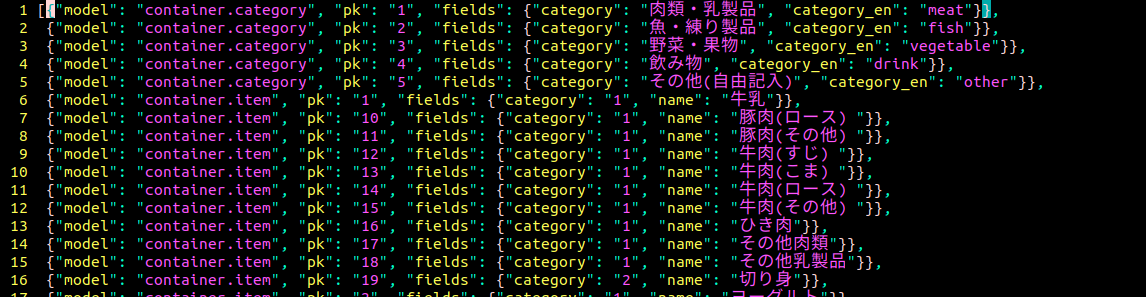
json形式でダンプされ、そのままでは改行が施されていないので、}},の次に改行を設置する。vimなら下記正規表現を実行
s/}},/}},\r/g
整形して表示された。後は矩形選択でまとめて一気に編集可能。
用途
元データを維持した状態でモデルの構成を書き換える場合、開発環境で作成・使用したデータをそのまま本番環境でも使用したい場合などに使う。
上記コマンドでダンプさせた後、下記loaddataコマンドでリストアさせれば良い。
python3 manage.py loaddata [アプリ名]/fixture/data.json
【関連記事】Djangoで開発中、データベースへ初期データを入力する【loaddata】
【注意】Windowsでdumpdataでバックアップしたjsonファイルのデータを、loaddataでリストアする場合【文字コード問題】
Windowsでloaddataとdumpdataを使って、データのバックアップとリストアをする場合、下記のコマンドで実現できるが、
python manage.py dumpdata [アプリ名] > [アプリ名]/fixture/data.json
python manage.py loaddata [アプリ名]/fixture/data.json
loaddataの実行に失敗する。
Windowsではターミナルに出力される文字コードがUTF-8ではないため、dumpdataコマンドを実行してjsonファイルを作る際、UTF-8ではない文字コードで保存されてしまう。
当然、そのjsonファイルをloaddataで読み込もうとしても文字コードエラーが出てしまうのだ。
これを解決するには、上記のdumpdataのコマンドででバックアップを取った後、別のjsonファイルを作り、内容をコピペして保存。loaddataを実行して読み込みするファイルは別のjsonファイルの名前を指定する。
このようにWindowsの場合に限り、dumpdataコマンドで作った後、手動で別ファイルに書き直す手間(UTF-8に変換する手間)が発生してしまうのだ。
そのため、このコマンドの再現はLinux系OSもしくはMacOS系で行うと良いだろう。それらのOSはデフォルトでターミナルの文字コードはUTF-8としており、Windowsとは違って文字コードによる問題は発生し得ないからである。