Pythonで画像認識AI(深層学習)の速習をするためのメモ【pytorchで画像認識学習・推論のサンプルあり】

急遽AI開発(特に画像認識)が必要になったため、それに必要な用語や概念的なものをまとめる。
ほとんどがChatGPTの受け売りである。自分用にまとめたのでかなり雑であることをお許しいただきたい。
そもそも機械学習と深層学習の違いは?
なんとなくだったため、この際はっきりさせる。
機械学習
簡単な表データを学習して推論したい場合、機械学習が有効。
データ量は数千〜数万件単位でOK。特徴量の設定は手動で行う必要があるが、CPUで計算でき負荷はそれほどかからない。
深層学習
ディープラーニングというものである。
画像や音声、自然言語処理であれば深層学習が有効。
データ量は数十万〜数百万件必要になる。特徴量は自動的に学習していくので、学習の設定は機械学習ほど複雑ではない。
機械学習に比べて複雑な処理が必要。高速化をさせるには、NVIDIAのグラフィックボードが必須。
深層学習の用語まとめ
- 特徴量
- 例えば犬の画像を犬と認識できる要素のこと。数値化されている。
- 深層学習ではこの特徴量の設定を自動的に行っているので、画像や音声などの複雑なデータの学習には非常に有効。
- 学習モデル
- 学習モデルの静的・動的
- 物体検出
- 領域抽出
- 量子化
- 畳み込み層
- プーリング層
- 全結合層
- 全結合層のみで構成されたものは、畳み込みニューラルネットワークではなく、多層パーセプトロンという
Pythonで代表的な深層学習ライブラリ
主には
- PyTorch
- TensorFlow
- Keras
この3つ。
PyTorch
Metaが開発した研究・プロトタイプ作成には人気のライブラリ。
コードが直感的で学習コストは比較的低め。
学習モデルの定義が動的になっている。
最適化次第でTensorFlow並の速度が出せる。
TensorFlow
高速な深層学習ライブラリ。産業用AIの開発には非常に有効。
ただし、PyTorchやKerasに比べてコードが複雑。
学習モデルの定義が静的であり動的である。
Keras
とても簡単に扱うことができるライブラリ。
中身はTensorFlowのため、速度は非常に遅い。
とりあえず深層学習を試したい人向け。
産業用AI開発が目的であれば何をするべきか?
TensorFlowかPyTorchの2択である。
特に悠長にKerasを使っている時間がない場合は、この内どちらかを採用する。
Pytorchで基本的な画像認識ができるサンプルコード
学習と推論までが一貫してできるサンプルコードをここに用意した。
requirements.txt は以下の通り。
filelock==3.17.0
fsspec==2025.2.0
Jinja2==3.1.5
MarkupSafe==3.0.2
mpmath==1.3.0
networkx==3.4.2
numpy==2.2.3
nvidia-cublas-cu12==12.4.5.8
nvidia-cuda-cupti-cu12==12.4.127
nvidia-cuda-nvrtc-cu12==12.4.127
nvidia-cuda-runtime-cu12==12.4.127
nvidia-cudnn-cu12==9.1.0.70
nvidia-cufft-cu12==11.2.1.3
nvidia-curand-cu12==10.3.5.147
nvidia-cusolver-cu12==11.6.1.9
nvidia-cusparse-cu12==12.3.1.170
nvidia-cusparselt-cu12==0.6.2
nvidia-nccl-cu12==2.21.5
nvidia-nvjitlink-cu12==12.4.127
nvidia-nvtx-cu12==12.4.127
pillow==11.1.0
sympy==1.13.1
torch==2.6.0
torchvision==0.21.0
triton==3.2.0
typing_extensions==4.12.2
以下がコードである。AIの知識がほとんどない状態のため、コメントが冗長気味ではある。
# ChatGPT製 50枚の犬画像から学習をして、100枚の画像をテストする。
# trainフォルダに、犬と猫の画像を含んだフォルダを用意する。 trainの中にcat とdogのフォルダ
# testフォルダにも、犬と猫の画像があるフォルダをそれぞれ用意する。testの中にcat とdogのフォルダ
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import os
# デバイス設定
# cudaが有効であればcudaを使う、そうでなければcpuを使う。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 画像の前処理
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# データセットの準備
train_dir = "./train" # 50枚の犬の画像フォルダ
test_dir = "./test" # 100枚の画像フォルダ
# TIPS: 画像データ(画像ならpngでもjpgでもbmpでもOK)を再帰的に取り込んでいる
# transform で画像を加工(前処理)している。
train_dataset = datasets.ImageFolder(root=train_dir, transform=transform)
test_dataset = datasets.ImageFolder(root=test_dir, transform=transform)
# ↑trainディレクトリ内にあるディレクトリごとに順番に番号が振られる。
# 注意: 振られた番号は必ずしもアルファベット順ではない。.class_to_idx (辞書型)で確認をする。
print("=======================")
print(train_dataset.class_to_idx)
print(test_dataset.class_to_idx)
print("=======================")
# TIPS: batch_size とは、1回のミニバッチで何枚まとめて処理するか。今回は10枚にまとめて学習・推論をしている。
# バッチサイズが1だとノイズが多くなり不安定になる。極端に多いと、VRAMの大量消費や過学習になってしまう。
# 結論: GPUのVRAMに合わせてバッチサイズを決める。A2000 6GB で 128x128 なら 32~64付近。12GBなら 128のバッチサイズ指定も可能の模様
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=10, shuffle=False)
# シンプルな CNN モデル
class SimpleCNN(nn.Module):
# TIPS: 畳み込みニューラルネット(全結合層のみの多層パーセプトロンと違い、全結合層+畳み込み層を持つ)
# 1枚画像 (3ch) → 畳み込み (16ch) → ReLU → プーリング
# このコンストラクタでレイヤーの定義をしている。
def __init__(self):
super(SimpleCNN, self).__init__()
# ↓畳み込み層 入力チャンネルは3、出力チャンネルは16、 カーネルサイズで3x3のフィルター、strideで1ずつずらす。paddingで周囲を1ピクセルだけ0で埋める(サイズ維持のため)
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
# ↓プーリング層 画像サイズを半分にする。 128x128 → 64x64
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
# ↓全結合層 ↓ プーリングで半分のサイズになっている。
self.fc1 = nn.Linear(16 * 64 * 64, 2)
# ↑ 今回は2種類に分類するため、この部分が2になっている。
# 10種類以上のフォルダであれば、10にする必要がある。フォルダの数が任意であれば、事前にカウントしておく必要がある。
# ↓ Recified Liner Unit ランプ関数。負をゼロにして、正の値はそのままにする。
self.relu = nn.ReLU()
# ↑で定義したレイヤーを発動させるメソッド。データを受け取った時内部的に実行される。
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = x.view(x.size(0), -1)
x = self.fc1(x)
return x
# なぜコンストラクタでレイヤーを発動(forwardメソッドを動作)させないのか?
# → レイヤーを動かすのは、.to(device)でCUDAに移動させて、モデルにデータを渡した時、例: model(input) を実行する時にforward メソッドが動く。
# なぜコンストラクタでレイヤーを定義しているのか?
# 定義したレイヤーを .to(device) で GPUに転送させるため。
# モデル、損失関数、最適化手法の定義
model = SimpleCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# TIPS: ハイパーパラメータ。5回学習をする。ここは通常は30回~50回ぐらい繰り返す
num_epochs = 5
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
# TIPS: 前処理した画像を1つずつ取り出しCUDAに移動。SimpleCNNのmodelにデータを与えforward(レイヤー) を動かす。
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
# TIPS:損失関数としてクロスエントロピー、最適化にAdamを使っている。
# クロスエントロピーは他クラス分析(犬猫の2分類にも、犬猫うさぎ鳥などの多分類にも有効)
# Adamは学習率を自動調整してくれるので扱いが簡単
# 注意: この学習のチューニングはハードウェアの性能なども考慮して変更する!!
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss/len(train_loader)}")
# TIPS: ここで、推論したモデルを保存する。次回以降、ファイルをロードすれば推論だけで済む。
# torch.save(model.state_dict(), "simple_cnn.pth")
# model.load_state_dict(torch.load("simple_cnn.pth"))
# 推論(100枚の画像を分類)
model.eval()
correct = 0
total = 0
# TIPS: この torch.no_grad() とは勾配計算を無効化するもの。
# → 学習をしないため勾配計算を無効化する。これにより高速化することができる。
with torch.no_grad():
# TIPS: データローダーのオブジェクト。使えるメソッドと属性は
# __iter__():forループでバッチを取り出す
# batch_size:バッチサイズ
# dataset:元データセット
# shuffle:シャッフル設定
# sampler:データのサンプリング方法
# <torch.utils.data.dataloader.DataLoader object at 0x7fbc50f2ec80>
print(test_loader)
print(train_loader)
# TIPS: test_loader からlabelsを取得している。このlabelsは数値でありフォルダ名ではない。.class_to_idx を使って辞書からフォルダ名を取り出せば良い。
# TIPS: バッチサイズは10なので、10枚の画像ずつで取り出している。1回しかループされないのは、フォルダ内の画像が10枚に満たないから。
for images, labels in test_loader:
# 画像とラベルをcudaへセット。推論をする。
images, labels = images.to(device), labels.to(device)
outputs = model(images)
# TIPS: 各クラスの確率orロジットの最大値 、推論結果(クラス番号)を返している、
_, predicted = torch.max(outputs, 1)
# TIPS: これは torch.tensor オブジェクト。 tensor.numpy() でnumpy配列に変換できる。
# tensor([15.8103, 16.2744, 4.7806, 7.7627, 9.1886, 8.4562, 13.3864], device='cuda:0')
# tensor([0, 0, 0, 0, 0, 1, 1], device='cuda:0')
# tensor([0, 0, 0, 0, 1, 1, 1], device='cuda:0')
print(_)
print(predicted)
print(labels)
# TIPS : 全体の数と正解数を取り出す。(predicted == labels).sum() バッチ内の正解数をカウント
correct += (predicted == labels).sum().item()
total += labels.size(0)
# 正解率
accuracy = 100 * correct / total
print(f"Test Accuracy: {accuracy:.2f}%")
サンプルコードからわかったことのまとめ
- 学習も推論も、画像をそのまま判定することはできないので、一度128x128のサイズにして学習と推論をする。
- 学習・推論にはバッチサイズ(1度に学習・推論をする画像の枚数)を指定することができる。ただし、VRAM性能によって上限がある。
- 学習と推論を効率よく行うためには、高性能なNvidiaグラフィックボードは不可欠。特にCUDAコア数とVRAM容量が重要。
- ニューラルネットワークの構造、最適なバッチサイズ、エポック数、その他のパラメータは、学習する画像に合わせてその都度調整する必要がある。
- だから、パラメータ等の最適解を導き出すためのプラットフォーム(DjangoなどのFW)の準備と開発は必須。(手作業でパラメータを変更して動かしているようでは時間がかかりすぎる。)
- 生成できた学習モデルを使って、推論のみをすることで、更なる高速推論を可能にする。
更に、TensorRTを使って量子化させることで、更なる高速化も期待できる。
高速推論を実現させるためには、学習の最適化だけでなく、システム設計の最適化も重要であり、AI開発のみで実現するものではない。
例えば、
- 1つのモデルに1枚ずつ画像を推論していくのではなく、まとめてN枚の画像を与えて、推論をさせる
- モデルを事前にロードして待機状態にしておく
- スケーラブルにするためにもAIの推論処理のみ別サーバーで行う
などがある。
これからすること
最後に、以上の速習を踏まえて、これからすることをまとめる。
ハイパーパラメーターチューニング
先の学習で取り決めたパラメータ(バッチサイズ、学習回数、レイヤーなど)は、学習をする画像の質や量によって大きく異なる。
そのため、最適と思われるパラメータを探査する必要がある。それが、ハイパーパラメーターチューニングである。
一般的に、このハイパーパラメーターチューニングはライブラリで行うことが多い。
代表的なものとして以下の4つがある。
- Optuna : ほぼデファクトスタンダード。直観的に使用できる
- Ray Tune : クラスタを使って大規模探査できる。スケーラブル。
- Hyperopt : ベイズ最適化に対応している。scikit-learnのように扱える
- Nevergrad : シンプルで進化的アルゴリズム多め
この中でもOptunaの扱い方から覚えていけば間違いはないだろう。
どのようなパラメータを指定したらどのように作用をするのか、それを知っていくことで、AI開発の前提知識として役立つとされている。
ハイパーパラメーターチューニングのプラットフォーム
もし、先のようなライブラリではなく、ウェブアプリ上で動作させる場合はプラットフォームを作る。
例えば、画像のフォルダをzipで圧縮してアップロードするだけで、学習とテストを自動的に行い、最適な学習モデルをDLできるプラットフォームが良いだろう。
汎用性を高めるためにも、DjangoとFastAPIを使って実現させる。
Django側でDB(学習結果等の記録)とファイルの管理、FastAPIで学習と推論を繰り返す。
パラメータはある程度手動で設定できるとして、その上限と下限を指定して、FastAPIが最適解を導く学習をする。
学習にかかった時間と、推論時間、正解率、学習モデルと、その他のパラメータの値はすべてDjangoのDBに保存し、後から学習モデルをDLできるようにする。
このしくみを実現させるためにも、高性能なNvidiaグラフィックボードが必要。
各学習結果をブラウザに表示させるためにも、動的なグラフの描画、chart.jsも必要だ。matplotlibでもグラフは作れるが、画像を生成してレスポンスをしているようでは即応性に欠ける。
もし可能であれば、FastAPIが学習を終えてDBに結果が記録されるたび、リアルタイムで学習結果ページに表示させたい。そうなるとWebSocketの実装は必須だ。学習の最適解の探査が終わっていなければ、進捗状況とかも表示させ、推定の残り時間とかも出すことができれば、なお良いだろう。
画面レイアウトを手書きでまとめるとこんな感じだろうか?
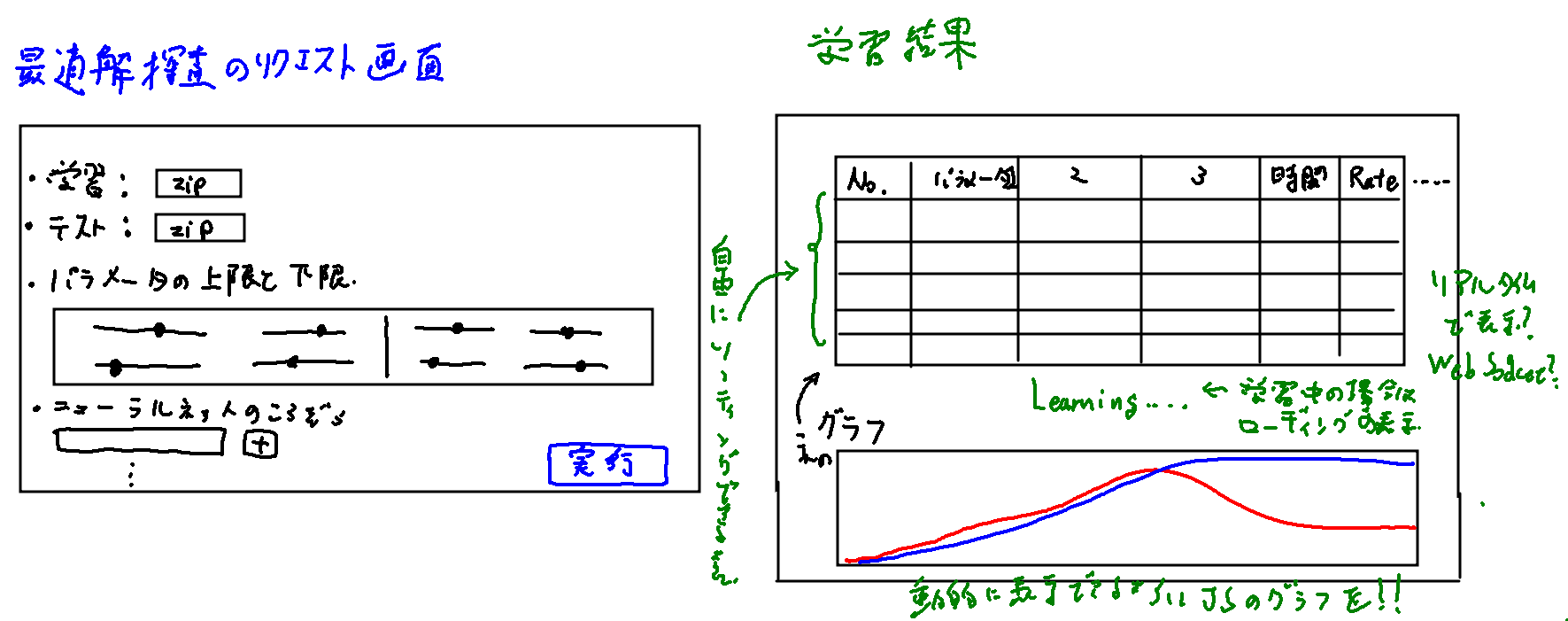
ただ、この探査作業、あまりパラメータの指定をしすぎると、何千通り、何万通りという探査になってしまう。だからこそ次項が必要だ。
数学と統計学の知識
前項で総当りツールを使えば一番効率の良い学習パラメータの探査ができるようになるが、そもそも数学や統計学の知識がないと、全くの的外れな上限と下限設定で、サーバーは無駄にリソースを消費するだけで終わる。
この探査の時間とリソースもタダではないので、事前に数学と統計学の勉強をしておき、アバウトでも良いので、ここからここまでの値で的確に学習を支持できるようにしておく。
単に動かすだけではなく、より高速に、より高精度で動作させるように仕立てていく。