Pythonで処理速度のボトルネックを特定する

Pythonの高速化には、ボトルネックの特定と改善が必要。
本記事ではボトルネックの特定をする。
関数の処理速度を調べるデコレータを用意する
以下のコードの関数をデコレータとして使うことで関数の処理時間を調べることができる。
from functools import wraps
import time
def timefn(fn):
@wraps(fn)
def meassure_time(*args, **kwargs):
start = time.time()
result = fn(*args, **kwargs)
print(f"@timefn デコレータより {fn.__name__} : {time.time() - start} 秒")
return result
return meassure_time
try_count = 10000000
@timefn
def create_numbers_for():
numbers = []
for i in range(try_count):
numbers.append(i)
create_numbers_for()
このtimefnはデコレータとして機能する。
def timefn(fn):
@wraps(fn)
def meassure_time(*args, **kwargs):
start = time.time()
result = fn(*args, **kwargs)
print(f"@timefn デコレータより {fn.__name__} : {time.time() - start} 秒")
return result
return meassure_time
デコレータは関数を包み込み(ラップ)、関数の動作や機能を拡張する仕組みのこと。
Djangoであれば@login_requireなどがデコレータに含まれる。これはビュー関数にログイン認証機能を追加している。
今回の timefn デコレータも関数の前方に、@timefnとすることで、処理時間を計測できる。
def timefn(fn):
このfn引数は、timefnがデコレータとしてラップする関数である。
@wraps(fn)
この wraps は 標準モジュールfunctools から from functools import wraps としてimportしている。
この wraps を使うことで、ラップする関数が元の関数名を維持することができる。
def meassure_time(*args, **kwargs):
start = time.time()
result = fn(*args, **kwargs)
print(f"@timefn デコレータより {fn.__name__} : {time.time() - start} 秒")
return result
この meassure_time 関数はラップした関数を実行し、その処理時間をtime.time() で計測している。
ラップした関数を正常に機能させるため、 *argsと**kwargsのパック引数、戻り値(result)のreturnをしている。
あとは、このデコレータを関数にラップする。
try_count = 10000000
@timefn
def create_numbers_for():
numbers = []
for i in range(try_count):
numbers.append(i)
create_numbers_for()
このように出力される。
@timefn デコレータより create_numbers_for : 0.6453492641448975 秒
あとはこのデコレータをエディタのスニペットに登録して、すぐに呼び出せるようにしておくと良いだろう。
cProfileモジュールでスクリプト全体の処理時間を計測する
先のデコレータは、処理時間の計測のため、コードを書き換えないといけない。
コードを書き換えずに処理時間を計測するには、cProfileモジュールを使う。
ただし、計測される処理時間は、スクリプト+cProfileの処理時間であり、単体で動かしたものではない点に注意。
python -m cProfile script.py
ただ、これでは関数がアルファベット順に表示されてしまう。処理時間の長い順に表示させるには、
python -m cProfile -s time script.py
とする。
例えば 非同期リクエスト vs マルチスレッドリクエスト vs 直列リクエスト のコードを cProfile で調べるとこうなる。
非同期処理結果: [27, 27, 27, 27, 27, .... ]
非同期処理時間: 0.48685455322265625
マルチスレッド処理結果: [27, 27, 27, 27, 27, .... ]
マルチスレッド処理時間: 5.682554721832275
直列処理結果: [27, 27, 27, 27, 27, .. ]
直列処理時間: 29.33954405784607
この通常の 処理のあとに、cProfileの結果が表示される。非常に長いため、一部のみ表示している。
2277634 function calls (2267993 primitive calls) in 35.731 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1199 26.158 0.022 26.158 0.022 {method 'recv_into' of '_socket.socket' objects}
4717 5.638 0.001 5.638 0.001 {method 'acquire' of '_thread.lock' objects}
7800 0.387 0.000 0.478 0.000 shlex.py:133(read_token)
1162 0.220 0.000 0.220 0.000 {method 'poll' of 'select.epoll' objects}
1200 0.091 0.000 0.314 0.000 request.py:2487(getproxies_environment)
7200 0.070 0.000 0.115 0.000 parse.py:456(urlsplit)
80400 0.063 0.000 0.148 0.000 os.py:698(__iter__)
80400 0.057 0.000 0.088 0.000 os.py:759(decode)
130200 0.053 0.000 0.060 0.000 {method 'read' of '_io.TextIOWrapper' objects}
130883/128463 0.052 0.000 0.092 0.000 {built-in method builtins.isinstance}
6600 0.046 0.000 0.189 0.000 parse.py:380(urlparse)
80400 0.043 0.000 0.191 0.000 _collections_abc.py:885(__iter__)
600 0.038 0.000 0.041 0.000 {built-in method io.open}
1800 0.037 0.000 0.056 0.000 url.py:227(_encode_invalid_chars)
1 0.037 0.037 0.037 0.037 {method 'load_verify_locations' of '_ssl._SSLContext' objects}
90600 0.036 0.000 0.036 0.000 {method 'decode' of 'bytes' objects}
15000 0.034 0.000 0.038 0.000 parse.py:123(_coerce_args)
126156/124320 0.032 0.000 0.035 0.000 {built-in method builtins.len}
130200 0.031 0.000 0.031 0.000 shlex.py:68(punctuation_chars)
12112 0.029 0.000 0.029 0.000 {method 'match' of 're.Pattern' objects}
以下略
このプロファイル結果から、socket モジュールの使用に26秒以上も時間を要したことがわかる。
1199 26.158 0.022 26.158 0.022 {method 'recv_into' of '_socket.socket' objects}
requestsとaiohttp は 内部的にsocketモジュールを使用している。それが今回の結果に出た。
更に、
4717 5.638 0.001 5.638 0.001 {method 'acquire' of '_thread.lock' objects}
ここでマルチスレッドのロックが発生している。マルチスレッドでグローバルなリストに要素をappend しているため(GILの制約を受ける)である。
ちなみに、マルチスレッドと直列のコードを削除し、非同期リクエストだけで実行、再度計測すると、
ncalls tottime percall cumtime percall filename:lineno(function)
1202 0.237 0.000 0.237 0.000 {method 'poll' of 'select.epoll' objects}
1900 0.015 0.000 0.100 0.000 client.py:470(_request)
1202 0.011 0.000 0.472 0.000 base_events.py:1832(_run_once)
226 0.010 0.000 0.010 0.000 {built-in method builtins.compile}
168 0.010 0.000 0.010 0.000 {built-in method marshal.loads}
1110 0.009 0.000 0.035 0.000 client_proto.py:239(data_received)
636/635 0.006 0.000 0.029 0.000 {built-in method builtins.__build_class__}
600 0.006 0.000 0.006 0.000 {method 'send' of '_socket.socket' objects} ← これが非同期リクエストの送信
4728 0.005 0.000 0.207 0.000 {method 'run' of '_contextvars.Context' objects}
600 0.005 0.000 0.020 0.000 client_reqrep.py:694(send)
1202 0.004 0.000 0.243 0.000 selectors.py:452(select)
4420 0.004 0.000 0.005 0.000 events.py:31(__init__)
4728 0.004 0.000 0.212 0.000 events.py:78(_run)
3518 0.004 0.000 0.008 0.000 base_events.py:772(_call_soon)
1200 0.004 0.000 0.011 0.000 client_reqrep.py:1048(start)
234/82 0.004 0.000 0.009 0.000 sre_parse.py:494(_parse)
600 0.003 0.000 0.008 0.000 client_reqrep.py:285(__init__)
1110 0.003 0.000 0.003 0.000 {method 'recv' of '_socket.socket' objects} ← 非同期リクエストでここまで高速化できる。
このように、socket モジュールの処理時間を大幅削減できるということだ。しかもマルチスレッドの競合による時間も削減できた。
つまり、非同期処理にすることで、I/O待機を効率的に処理できるだけでなく、同一のオブジェクトに対しての複数スレッドの競合も発生しなくなるということだ。
非同期処理はシングルスレッドで動いている、故にGILの影響を受けることはない。
マルチスレッドで動く場合は、GILの影響を受ける。ロックが発生し、これが原因で時間がかかっていたということになる。
cProfile の処理結果の保存と解析
ここで、処理結果を保存したいのであれば、
python -m cProfile -s time -o profile.prof script.py
とする。この profile.prof は テキストファイルではないので、エディタで開いても確認はできない。
そこで、pstats でテキスト解析。他にも snakeviz や gprof2dot を使う。
pstats モジュールでテキスト化
Pythonのインタラクティブシェルに入り
import pstats
pstats.Stats("profile.prof").strip_dirs().sort_stats("time").print_stats(20)
を実行する。
これで、
2278956 function calls (2269315 primitive calls) in 35.715 seconds
Ordered by: internal time
List reduced from 2804 to 20 due to restriction <20>
ncalls tottime percall cumtime percall filename:lineno(function)
1200 26.165 0.022 26.165 0.022 {method 'recv_into' of '_socket.socket' objects}
4729 5.678 0.001 5.678 0.001 {method 'acquire' of '_thread.lock' objects}
7800 0.377 0.000 0.466 0.000 shlex.py:133(read_token)
1265 0.234 0.000 0.234 0.000 {method 'poll' of 'select.epoll' objects}
1200 0.089 0.000 0.304 0.000 request.py:2487(getproxies_environment)
7200 0.068 0.000 0.112 0.000 parse.py:456(urlsplit)
80400 0.063 0.000 0.141 0.000 os.py:698(__iter__)
130200 0.052 0.000 0.060 0.000 {method 'read' of '_io.TextIOWrapper' objects}
80400 0.050 0.000 0.081 0.000 os.py:759(decode)
このようにコマンドからそのまま出力した場合と変わらず確認できる。
snakeviz を使って可視化
pip install snakeviz
でインストール、ターミナルから
snakeviz profile.prof
と実行すると、
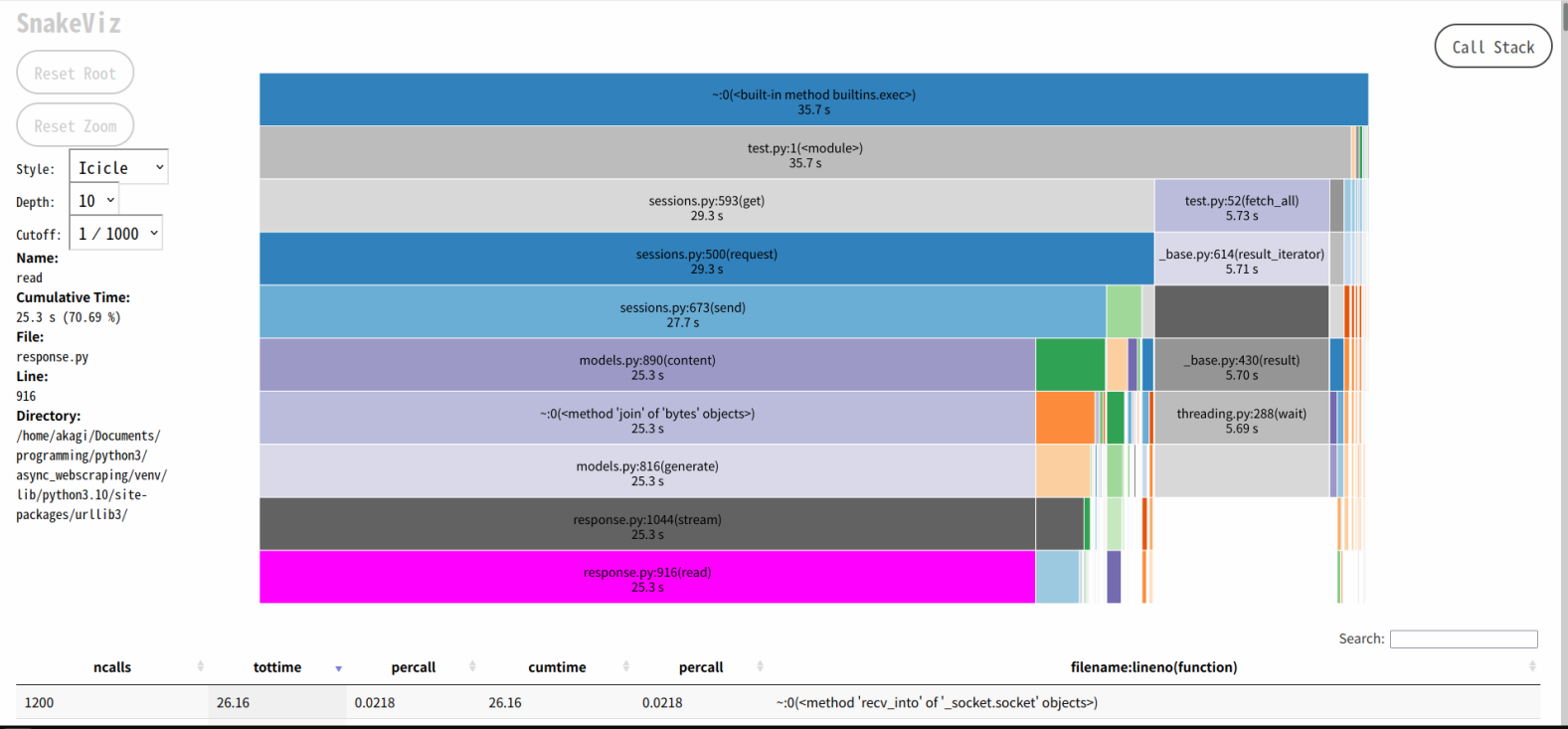
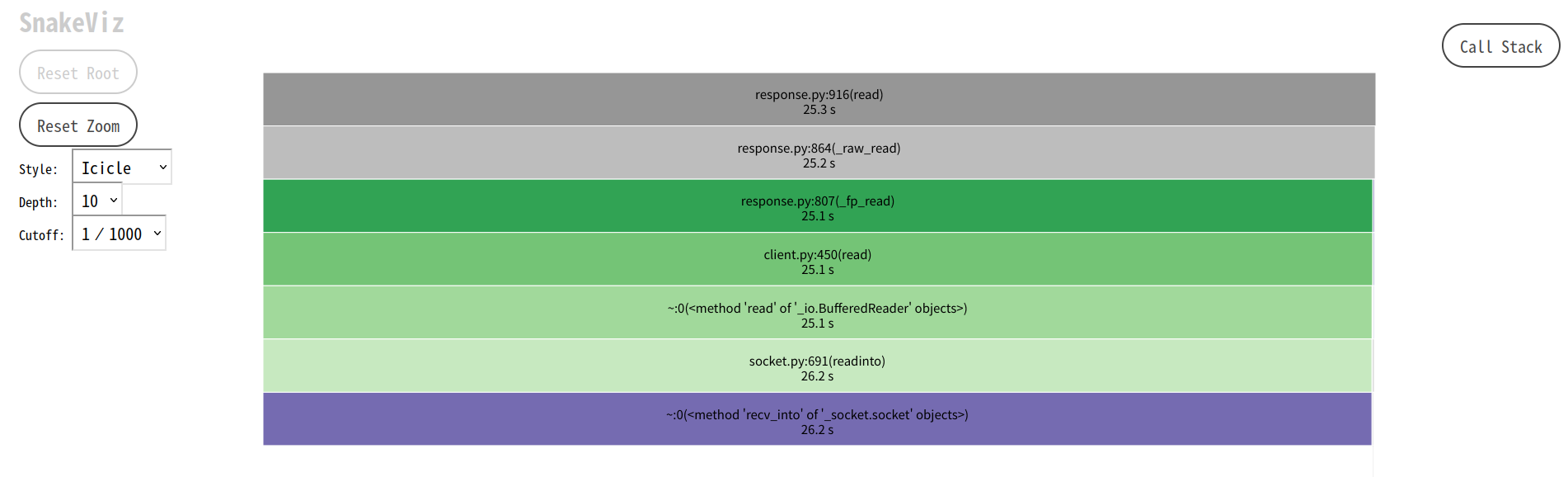
このようにレスポンスの読み込みに時間がかかっていることがわかる。クリックすると、更に詳細に確認できる。
gprof2dot でグラフ化
pip install gprof2dot
プロファイルの結果を関数のコールグラフで出力することができる。
gprof2dot -f pstats profile.prof | dot -Tpng -o profile.png
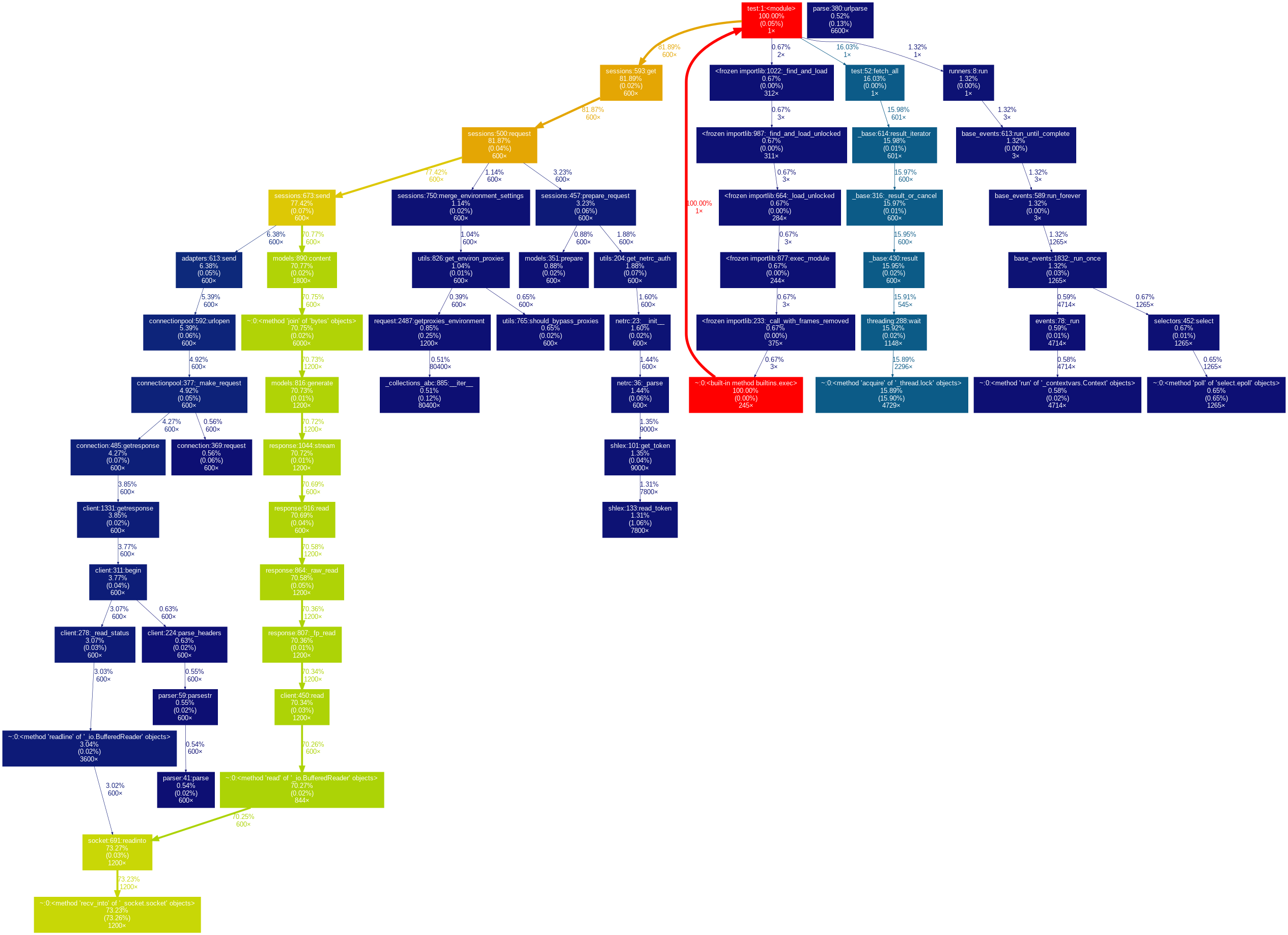
ここから、リクエスト関係に時間がかかっていることがわかる。
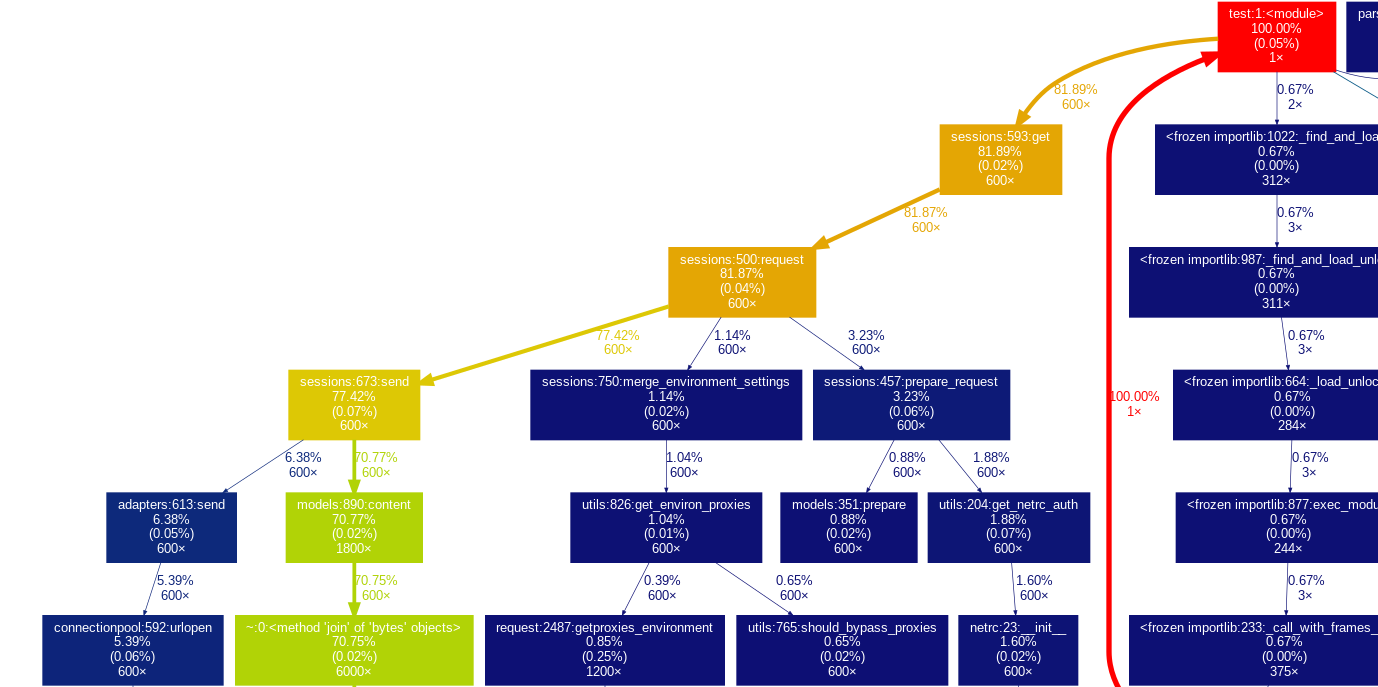
処理時間が大きい順に色分けされているようだ。
行単位で処理時間を計測する
line_profiler を使う。
pip install line_profiler
任意の関数に、@profileデコレータを設置。その上で、karnprofコマンドを使う
kernprof -l -v test.py
実行すると、通常の出力が終わったあと
Total time: 29.9279 s
File: test.py
Function: fetch_url at line 49
Line # Hits Time Per Hit % Time Line Contents
==============================================================
49 @profile
50 def fetch_url(session, url):
51 1200 29921247.7 24934.4 100.0 with session.get(url) as response:
52 600 5988.1 10.0 0.0 data = response.text
53 600 667.0 1.1 0.0 return len(data)
このように、行単位で使用された時間がわかる。
行単位でメモリ使用量を計測する
memory_profiler を使う。
pip install memory_profiler
任意の関数に、@profileデコレータを設置。その上で、mprofもしくはpython -m memory_profilerを使う。
python -m memory_profiler test.py
mprof run test.py
メモリ使用量がわかる。
Filename: test.py
Line # Mem usage Increment Occurrences Line Contents
=============================================================
55 35.828 MiB 35.828 MiB 1 @profile
56 def fetch_all(urls):
57 36.871 MiB 0.000 MiB 2 with requests.Session() as session:
58 36.871 MiB 0.355 MiB 2 with ThreadPoolExecutor(max_workers=5) as executor:
59 36.516 MiB 0.688 MiB 1 results = list(executor.map(lambda url: fetch_url(session, url), urls))
60 36.871 MiB 0.000 MiB 1 return results
結論
以上のプロファイルにより、
- requestsやaiohttp は内部でsocket モジュールを使用している
- マルチスレッドはGILの影響によりロックされ、逆に時間がかかる(普通の直列処理よりはマシ)
- 非同期処理はI/O待機問題の解決だけでなく、マルチスレッドのロック問題も発生しない
などがわかるようになった。
自分の直感ではなく、客観的なデータに基づいて高速化していくことが、いかに重要であるかが思い知らされる。