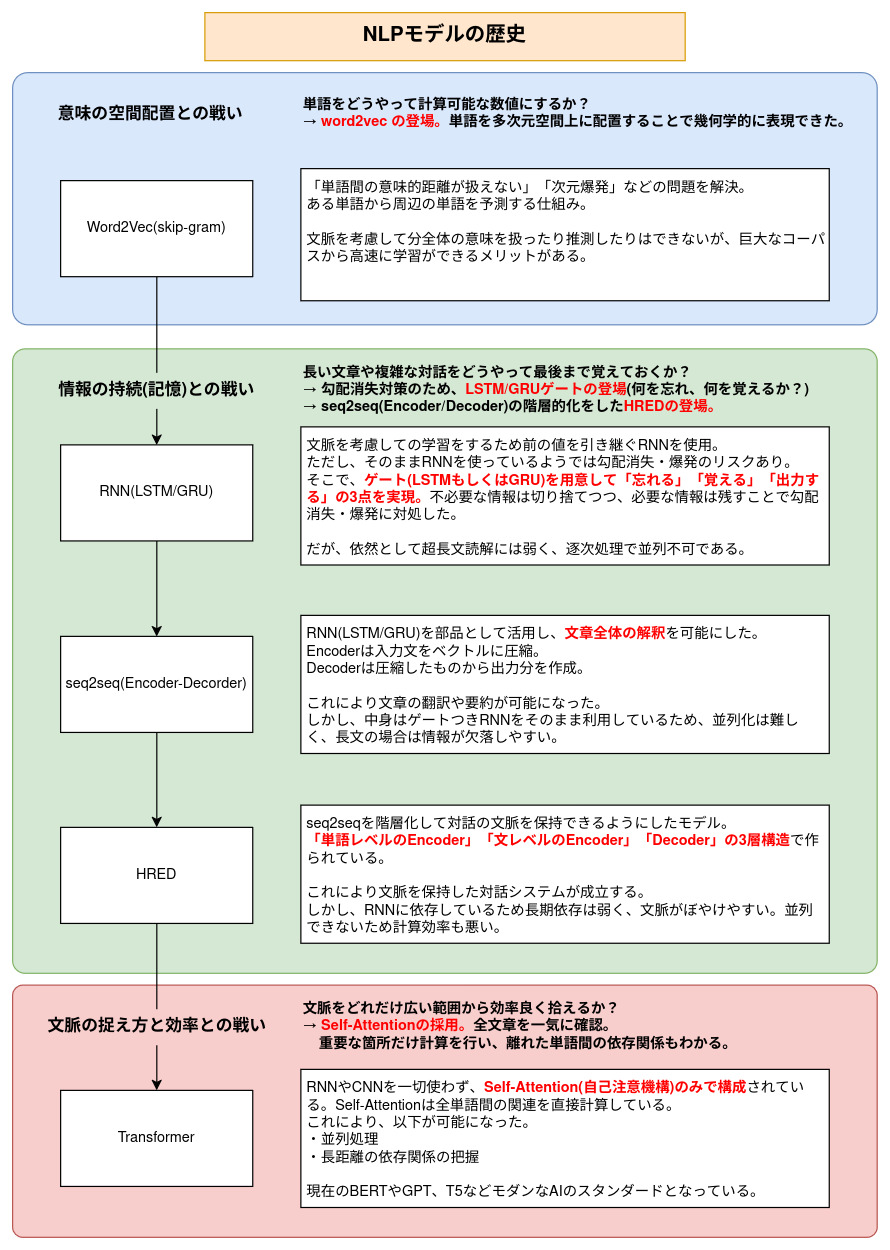
pytorchコードでNLPモデルの歴史を辿る【word2vec から Transformerまで 】

俯瞰
自然言語処理の入力仕様
Transformer よりも前のモデルには、単語間の関連を理解するための入力仕様が用意されている。
Tokenizerで数値化し、その数値を使いEmbeddingで特徴量のリストを作っている。
Transformerには、Embedding層が用意されている。
Tokenizer
Tokenizerは入力値を単語に分けてIDを振る
入力値: "I love AI"
↓
単語に分ける: ["I","love","AI"]
↓
IDを振る: [ 5, 101, 61 ]
このTokenizerにより、単語を数値として計算可能な形にしている。
Embedding
Embeddingは、単語のIDを連続ベクトル(特徴量のリスト)に変換する。
例えば以下のようなイメージである。
- リンゴ: [0.9, 0.1, 0.5] (食べ物度, 生き物度, 赤さ)
- バナナ: [0.9, 0.1, 0.1] (食べ物度, 生き物度, 黄色さ)
- ゴリラ: [0.1, 0.9, 0.2] (食べ物度, 生き物度, 黒さ)
実際のEmbeddingは、いきなり単語→連続ベクトルは作れない(幾何学的な計算を経由する必要があるため)
そのため、一旦Tokenizerで数値化(ID化)させる必要がある。
Word2Vec(Skip-gram)
単語を固定長のベクトルに変換し、幾何学的な計算が可能な状態にしている。
意味を数値化することで、Embeddingとして後続のモデルに入力可能な形にしている。
とりわけ、skip-gram はCBOWとは異なり、1つの単語から 2つ単語を学習することができる。
この手法を使うことでより高速にEmbeddingを手に入れることができる。
コード
import torch
import torch.nn as nn
import torch.optim as optim
# 1. データの準備
# 「私は AI が 好き」という文章を想定
# (中心語, 周辺語1), (中心語, 周辺語2) のペアを作成
# 今回は「AI」から「私は」と「が」を学習するペアを用意
data = [
("AI", "私は"),
("AI", "が"),
]
# 単語とIDの対応付け (Tokenizerの簡易版)
word_to_ix = {"私は": 0, "AI": 1, "が": 2, "好き": 3}
ix_to_word = {i: w for w, i in word_to_ix.items()}
vocab_size = len(word_to_ix)
# 2. Skip-gramモデルの定義
class SkipGramModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(SkipGramModel, self).__init__()
# これが「Embedding層(重み)」
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# 予測のための全結合層
self.linear = nn.Linear(embedding_dim, vocab_size)
def forward(self, inputs):
# IDをベクトルに変換
embeds = self.embeddings(inputs) # (batch_size, embedding_dim)
# ベクトルから各単語の出現確率(スコア)を計算
out = self.linear(embeds) # (batch_size, vocab_size)
return out
# 3. 学習の準備
EMBEDDING_DIM = 10 # 特徴ベクトルの次元数
model = SkipGramModel(vocab_size, EMBEDDING_DIM)
loss_function = nn.CrossEntropyLoss() # 多値分類の損失関数
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 4. 学習ループ
print("学習を開始します...")
for epoch in range(100):
total_loss = 0
for target, context in data:
# 入力(中心語)と正解(周辺語)をIDに変換
target_idx = torch.tensor([word_to_ix[target]], dtype=torch.long)
context_idx = torch.tensor([word_to_ix[context]], dtype=torch.long)
# 勾配の初期化
model.zero_grad()
# 順伝播
log_probs = model(target_idx)
# 損失の計算
loss = loss_function(log_probs, context_idx)
# 逆伝播と重みの更新
loss.backward()
optimizer.step()
total_loss += loss.item()
# 5. 結果の確認(「AI」を入力して周辺語を予測させてみる)
with torch.no_grad():
test_word = "AI"
test_idx = torch.tensor([word_to_ix[test_word]], dtype=torch.long)
prediction = model(test_idx)
# スコアの高い上位2単語を表示
top_values, top_indices = torch.topk(prediction[0], 2)
print(f"\n入力単語: {test_word}")
print(f"予測された周辺語:")
for idx in top_indices:
print(f" - {ix_to_word[idx.item()]}")
# 6. Embedding(特徴ベクトル)の取り出し
print(f"\n単語 '{test_word}' のEmbedding(最初の5次元):")
print(model.embeddings.weight[word_to_ix[test_word]][:5])
RNN + LSTM/GRU
RNN は時系列データを扱うことができるニューラルネットワークである。これにより単語単位ではなく文単位の意味を学習することができる。
しかしRNNにも弱点があり、長文を学習していると最初の単語の情報を忘れてしまう(勾配消失をおこしてしまう。)
そこで、この勾配消失問題を改善するため、ゲートつきRNN(LSTM/GRU)が考案された。
何を覚えて、何を忘れ、何を出力するか、その制御をしている。
ゲートを導入しても勾配消失問題は完全には改善はされなかったが、単語ではなく、長文を学習できるという点ではWord2Vecより優れている。
コード
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(LSTMModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# LSTM層: hidden_dimは「記憶の容量」のようなもの
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
# 最終的な単語予測のための層
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, hidden=None):
# x: (batch, seq_len) -> embeds: (batch, seq_len, embed_dim)
embeds = self.embedding(x)
# lstm_out: 各ステップの出力
# hidden: (h_n, c_n) つまり「短期記憶」と「長期記憶(セル状態)」
lstm_out, hidden = self.lstm(embeds, hidden)
# 最後の単語の出力を使って次の単語を予測
out = self.fc(lstm_out)
return out, hidden
# パラメータ設定
vocab_size = 5000
model = LSTMModel(vocab_size, embedding_dim=128, hidden_dim=256)
# 入力例: [私は, AI, が] というIDの並び (1, 3)
input_data = torch.randint(0, vocab_size, (1, 3))
output, (hn, cn) = model(input_data)
print(f"LSTM出力サイズ: {output.shape}") # (1, 3, 5000) -> 各ステップでの予測
print(f"隠れ状態(h_n)サイズ: {hn.shape}") # (1, 1, 256) -> 文の「要約」
seq2seq (Sequence-to-Sequence)
RNN+LSTM/GRU により長文の学習が可能になった。
この長文の学習を翻訳に利用したのが seq2seq である。
RNN+LSTMを部品として利用し、入力を担当するEncoderと出力を担当するDecoderの2つを利用している。
コード
import torch
import torch.nn as nn
# --- Encoder: 入力文を「一つの記憶」に詰め込む ---
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, batch_first=True)
def forward(self, src):
# outputsは捨てて、最後のhidden(記憶)だけをDecoderに渡す
outputs, (hidden, cell) = self.rnn(self.embedding(src))
return hidden, cell
# --- Decoder: Encoderの記憶を元に、新しい文を生成する ---
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim):
super().__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, batch_first=True)
self.fc_out = nn.Linear(hid_dim, output_dim)
def forward(self, input, hidden, cell):
# inputは1単語ずつ処理する
input = input.unsqueeze(1)
embedded = self.embedding(input)
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
prediction = self.fc_out(output.squeeze(1))
return prediction, hidden, cell
# --- Seq2Seq: EncoderとDecoderを繋げる ---
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, trg_len, vocab_size):
# 1. Encoderで入力文を圧縮
hidden, cell = self.encoder(src)
# 2. Decoderで1単語ずつ生成
# 最初は<SOS>(開始)トークンからスタート(ここでは仮にID:1)
input = torch.tensor([1])
outputs = []
for t in range(trg_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs.append(output)
# 最も確率の高い単語を次の入力にする
input = output.argmax(1)
return torch.stack(outputs)
# モデルの構築
enc = Encoder(input_dim=5000, emb_dim=128, hid_dim=256)
dec = Decoder(output_dim=5000, emb_dim=128, hid_dim=256)
model = Seq2Seq(enc, dec)
# 実行例
src_sentence = torch.randint(0, 5000, (1, 5)) # 5単語の入力文
result = model(src_sentence, trg_len=5, vocab_size=5000)
print(f"Seq2Seq出力サイズ: {result.shape}") # (5, 1, 5000) -> 5単語生成
HRED (Hierarchical Recurrent Encoder-Decoder)
Hierarchical (階層的) にseq2seq を利用した学習モデルである。
seq2seqは直前の発話に対してしか反応できなかったが、HREDは
- 単語レベルのEncoder (直前の1文章)
- 文レベルのEncoder (それまでの文章の流れ)
- Decoder (出力)
の構成にすることで、過去のやり取りを踏まえた応答生成を可能にした。これにより簡易的なチャットボットが作れる。
コード
import torch
import torch.nn as nn
class HRED(nn.Module):
def __init__(self, vocab_size, embed_dim, hid_dim):
super().__init__()
# 1. 単語レベル Encoder (文の中身を理解する)
self.word_encoder = nn.LSTM(embed_dim, hid_dim, batch_first=True)
# 2. 文レベル Encoder (対話の文脈・流れを記憶する)
# 入力は word_encoder の出力ベクトル (hid_dim)
self.context_encoder = nn.LSTM(hid_dim, hid_dim, batch_first=True)
# 3. Decoder (対話の記憶を元に返答を作る)
self.decoder = nn.LSTM(embed_dim, hid_dim, batch_first=True)
self.fc_out = nn.Linear(hid_dim, vocab_size)
def forward(self, dialogue_batch):
# dialogue_batch: (発話数, 単語数)
# --- ステップ1: 各発話をベクトル化 ---
utterance_vectors = []
for utterance in dialogue_batch:
_, (hn, _) = self.word_encoder(utterance) # 最後の隠れ状態を取得
utterance_vectors.append(hn)
# --- ステップ2: 対話の流れを更新 ---
# 過去の発話ベクトルを順番に Context RNN に通す
context_input = torch.stack(utterance_vectors)
_, (context_hn, _) = self.context_encoder(context_input)
# --- ステップ3: 次の返答を生成 ---
# context_hn (対話の要約) を初期状態として Decoder を動かす
# ... (以下 seq2seq の Decoder 処理と同様)
Transformer
これまでのRNNを使用したモデルから一新して、Self-Attention(自己注意機構)をベースにして構成されたモデル。
- 文章全体を並列的に高速処理できる
- 離れた単語間の関係が正確に捉えられる
という特徴がある。現代のBERTやGPTなどのモダンAIモデルのベースとなっている。
Self-AttentionはこれまでのRNNの左から右に進む形ではなく、すべての文章から単語間の関連を学習している。
その重要度の根拠は「Query(問)」「Key(鍵)」「Value(値)」の3つのベクトル同士の相性度によって決まる。
例えば、カレーの作り方を調べているとする。
- Query: 「カレーの作り方」というキーワード
- Key: 「インドカレー入門」「スパイス講座」「誰でもかんたんカレーライス」などと言った本の背表紙
- Value: それらの本を開いたときに得られる実際の情報
がそれぞれ該当する。
キーワード(Query) と単語(Key)との相性で重要度(スコア)で決定。スコアに基づいて単語の情報(Value)を加重平均(ブレンド)して取り込んでいる。
Word2Vec は単語間の関連を数値計算によって求めたのに対して、TransformerのSelf-Attentionは単語間の関連の数値計算に加え、単語の情報も踏まえて重要度の取り決めしている。
しかも、RNNと違って左から右の一方通行ではなく、全体の文章を並列的に双方向的に処理できる点で大きく異なる。
コード
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleTransformerEncoder(nn.Module):
def __init__(self, vocab_size, d_model, nhead, dim_feedforward):
super().__init__()
# 1. Embedding層: IDを特徴ベクトルに変換
self.embedding = nn.Embedding(vocab_size, d_model)
# 2. Positional Encoding: RNNを使わない代わりに「単語の順番」の情報を足す
# 本来はサイン波などで作りますが、ここでは簡略化のため学習可能なパラメータにします
self.pos_embedding = nn.Parameter(torch.zeros(1, 100, d_model))
# 3. Transformer Layer (これが文全体を並列処理する心臓部)
# 内部で Multi-Head Self-Attention が動いています
self.transformer_layer = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=nhead,
dim_feedforward=dim_feedforward,
batch_first=True
)
def forward(self, x):
# x: (batch_size, seq_len) -> IDの並び
# --- ステップ1: Embedding (並列実行) ---
seq_len = x.size(1)
x = self.embedding(x) # (batch, seq_len, d_model)
# 位置情報を加算
x = x + self.pos_embedding[:, :seq_len, :]
# --- ステップ2: Self-Attention & 並列処理 ---
# ここでRNNのようなループは回らず、全単語が一斉に計算されます
attn_output = self.transformer_layer(x)
return attn_output
# パラメータ設定
VOCAB_SIZE = 5000
D_MODEL = 512 # 特徴ベクトルの次元数
N_HEAD = 8 # Attentionの数 (Q, K, Vを8セット並列で動かす)
model = SimpleTransformerEncoder(VOCAB_SIZE, D_MODEL, N_HEAD, 2048)
# 入力例: 10単語からなる文章が 1つ
input_data = torch.randint(0, VOCAB_SIZE, (1, 10))
# 実行
output = model(input_data)
print(f"入力サイズ: {input_data.shape}") # (1, 10)
print(f"出力サイズ: {output.shape}") # (1, 10, 512)