pytorch の nn.moduleを継承して自作AIモデルを作り、CNNモデルの歴史を辿る

CNNの歴史。
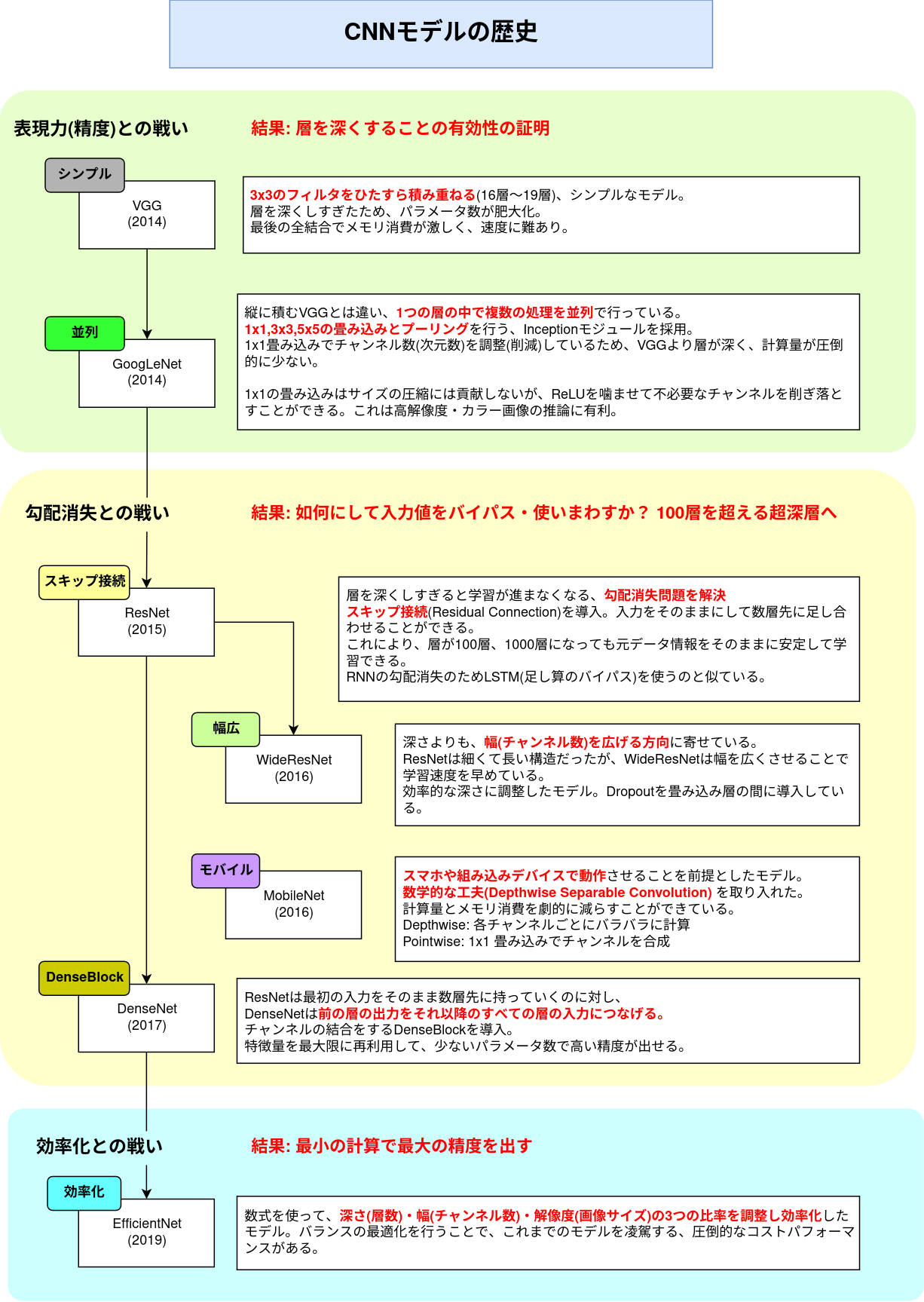
この歴史に沿って、FassionMNISTに対し、nn.moduleで各AIモデルに沿ったモデルを作る。
VGG
3x3 の畳み込みをただ深く積み重ねる
class VGG_Fashion(nn.Module):
def __init__(self):
super(VGG_Fashion, self).__init__()
self.features = nn.Sequential(
# Block 1
nn.Conv2d(1, 32, 3, padding=1), nn.ReLU(),
nn.Conv2d(32, 32, 3, padding=1), nn.ReLU(),
nn.MaxPool2d(2), # 14x14
# Block 2
nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(),
nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(),
nn.MaxPool2d(2) # 7x7
)
self.classifier = nn.Sequential(
nn.Linear(64 * 7 * 7, 512), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(512, 10)
)
GoogLeNet
1x1 フィルタを使用して次元数を削減している。(※ 5x5 畳み込みはサイズの都合上、省略)
class InceptionModule(nn.Module):
def __init__(self, in_ch, out_1x1, out_3x3):
super().__init__()
self.branch1 = nn.Conv2d(in_ch, out_1x1, kernel_size=1)
self.branch2 = nn.Sequential(
nn.Conv2d(in_ch, out_3x3//2, kernel_size=1),
nn.Conv2d(out_3x3//2, out_3x3, kernel_size=3, padding=1)
)
def forward(self, x):
return torch.cat([self.branch1(x), self.branch2(x)], 1)
class GoogLeNet_Fashion(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 32, 3, padding=1),
InceptionModule(32, 32, 32), # 32+32=64ch
nn.MaxPool2d(2), # 14x14
InceptionModule(64, 64, 64), # 64+64=128ch
nn.MaxPool2d(2) # 7x7
)
self.classifier = nn.Linear(128 * 7 * 7, 10)
ResNet
入力値を足し合わせて、勾配消失を防ぐ。
class ResidualBlock(nn.Module):
def __init__(self, ch):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(ch, ch, 3, padding=1), nn.BatchNorm2d(ch), nn.ReLU(),
nn.Conv2d(ch, ch, 3, padding=1), nn.BatchNorm2d(ch)
)
def forward(self, x):
return nn.functional.relu(x + self.conv(x)) # 足し算
class ResNet_Fashion(nn.Module):
def __init__(self):
super().__init__()
self.prep = nn.Sequential(nn.Conv2d(1, 64, 3, padding=1), nn.ReLU())
self.layer1 = ResidualBlock(64)
self.pool = nn.MaxPool2d(4) # 一気に 7x7 へ
self.classifier = nn.Linear(64 * 7 * 7, 10)
WideResNet
チャンネル数(特徴に対する視点)を増やすことで、層の深さよりも幅を広げている。
class WideResNet_Fashion(nn.Module):
def __init__(self):
super().__init__()
# チャンネル数を通常のResNetより大幅に増やす(例: 128)
self.features = nn.Sequential(
nn.Conv2d(1, 128, 3, padding=1),
nn.Dropout2d(0.3),
nn.Conv2d(128, 128, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(4)
)
self.classifier = nn.Linear(128 * 7 * 7, 10)
MobileNet
各チャンネルごとの計算と1x1合成に分離する。
class MobileBlock(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.dw = nn.Conv2d(in_ch, in_ch, 3, padding=1, groups=in_ch) # Depthwise
self.pw = nn.Conv2d(in_ch, out_ch, 1) # Pointwise (1x1)
def forward(self, x):
return nn.functional.relu(self.pw(self.dw(x)))
class MobileNet_Fashion(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
MobileBlock(1, 32), nn.MaxPool2d(2),
MobileBlock(32, 64), nn.MaxPool2d(2)
)
self.classifier = nn.Linear(64 * 7 * 7, 10)
DenseNet
前の層の出力を足し算ではなく、連結によって使いまわす。
class DenseNet_Fashion(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, 3, padding=1)
self.conv2 = nn.Conv2d(32, 32, 3, padding=1) # 32 + 32 = 64chになる
self.classifier = nn.Sequential(
nn.MaxPool2d(4),
nn.Linear(64 * 7 * 7, 10)
)
def forward(self, x):
x1 = nn.functional.relu(self.conv1(x))
x2 = nn.functional.relu(self.conv2(x1))
out = torch.cat([x1, x2], 1) # 連結
return self.classifier(out.view(out.size(0), -1))
EfficientNet
MBConvに SEBlock を加え各チャンネルの重要度の調整をしている。
class SEBlock(nn.Module): # チャンネル重要度の調整
def __init__(self, ch):
super().__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Linear(ch, ch//4), nn.ReLU(),
nn.Linear(ch//4, ch), nn.Sigmoid()
)
def forward(self, x):
return x * self.se(x.view(x.size(0), -1)).view(x.size(0), x.size(1), 1, 1)
class EfficientNet_Fashion(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 32, 3, padding=1),
SEBlock(32),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1),
SEBlock(64),
nn.MaxPool2d(2)
)
self.classifier = nn.Linear(64 * 7 * 7, 10)
結論
FassionMNISTは、白黒の1チャンネル構成であるため、既製のモデルを使った表現が困難。
今回はnn.Moduleを継承してその表現をした。
Efficientなどのモデルは、カラー(3ch)を前提としており、層も深いため、高解像度(100x100など)の画像の分類に真価を発揮する。
具体的にはCTL-10、Food101、Caltech-101/256 などが有用。