RTX A2000 12GBでOllama(Gemma7B:4bit量子化仕様)+QdrantでテキストファイルのRAGを実現

前提
- GPU: RTX A2000 12GB
- LLM: Ollama(Gemma-7B 4bit量子化仕様)
- RAG: Qdrant
上記環境下で、指定のディレクトリ内のテキストファイルをすべて読み込み、RAGを実現させる。
qdrantの立ち上げとOllama と Gemma 7B のインストール
Gemma 7Bのインストール。
ollama pull gemma:7b
すでにOllamaでは4bit量子化仕様を配布しているので、あえて指定をする必要はない。上記コマンドで4bit量子化仕様が手に入る。
続いてqdrantはdockerで起動させる
#! /bin/bash
docker run -d \
--name qdrant \
-p 6333:6333 \
-p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrant
curl http://localhost:6333
このcurlコマンドでJSONが返却されればOK。
必要なライブラリのインストール
pip install qdrant-client sentence-transformers ollama tqdm
ソースコード
ChatGPTに依頼したコードのため、内容までは深くは理解していない。あしからず。
後に解説を追記予定。
import os
from pathlib import Path
from typing import List
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance, PointStruct
from sentence_transformers import SentenceTransformer
import ollama
from tqdm import tqdm
# =========================
# 設定
# =========================
DATA_DIR = "./docs" # 対象ディレクトリ
COLLECTION_NAME = "rag_collection"
CHUNK_SIZE = 500
CHUNK_OVERLAP = 50
EMBEDDING_MODEL = "all-MiniLM-L6-v2"
LLM_MODEL = "gemma:7b"
# =========================
# 初期化
# =========================
qdrant = QdrantClient(host="localhost", port=6333)
embedder = SentenceTransformer(EMBEDDING_MODEL)
# =========================
# ユーティリティ
# =========================
def load_texts(directory: str) -> List[str]:
texts = []
for path in Path(directory).rglob("*.txt"):
with open(path, "r", encoding="utf-8") as f:
texts.append(f.read())
return texts
def chunk_text(text: str) -> List[str]:
chunks = []
start = 0
while start < len(text):
end = start + CHUNK_SIZE
chunk = text[start:end]
chunks.append(chunk)
start += CHUNK_SIZE - CHUNK_OVERLAP
return chunks
# =========================
# コレクション作成
# =========================
def create_collection():
if COLLECTION_NAME in [c.name for c in qdrant.get_collections().collections]:
print("Collection already exists")
return
qdrant.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(
size=384, # all-MiniLM-L6-v2
distance=Distance.COSINE
)
)
print("Collection created")
# =========================
# インデックス作成
# =========================
def index_documents():
texts = load_texts(DATA_DIR)
all_chunks = []
for text in texts:
all_chunks.extend(chunk_text(text))
print(f"Total chunks: {len(all_chunks)}")
embeddings = embedder.encode(all_chunks, show_progress_bar=True)
points = []
for i, (chunk, vector) in enumerate(zip(all_chunks, embeddings)):
points.append(
PointStruct(
id=i,
vector=vector.tolist(),
payload={"text": chunk}
)
)
qdrant.upsert(
collection_name=COLLECTION_NAME,
points=points
)
print("Indexing complete")
# =========================
# 検索
# =========================
def search(query: str, top_k=5):
query_vec = embedder.encode(query)
results = qdrant.query_points(
collection_name=COLLECTION_NAME,
query=query_vec,
limit=top_k
).points
return [r.payload["text"] for r in results]
# =========================
# RAG生成
# =========================
def rag(query: str):
contexts = search(query)
context_text = "\n\n".join(contexts)
prompt = f"""
以下のコンテキストを使って質問に答えてください。
[コンテキスト]
{context_text}
[質問]
{query}
"""
response = ollama.chat(
model=LLM_MODEL,
messages=[
{"role": "user", "content": prompt}
]
)
return response["message"]["content"]
# =========================
# 実行
# =========================
if __name__ == "__main__":
create_collection()
index_documents()
while True:
q = input("質問: ")
print(rag(q))
テキストファイルを用意する。
カレントディレクトリのdocsに以下記事のマークダウンを用意した。
./django-openpyxl.txt
./openpyxl-graph.txt
./startup-openpyxl.txt
./startup-pandas-openpyxl-matplotlib.txt
元はマークダウンになっており、以下から原文をDL可能。
https://github.com/seiya0723/noauto-nolife/tree/master/content/post
サイト内検索で 「openpyxl」 で検索すれば上記4つの原文が手に入る。それを今回は拡張子を.txtにした。
実際に動かしてみた。
プロンプト入力から出力まで1分弱といったところかと。
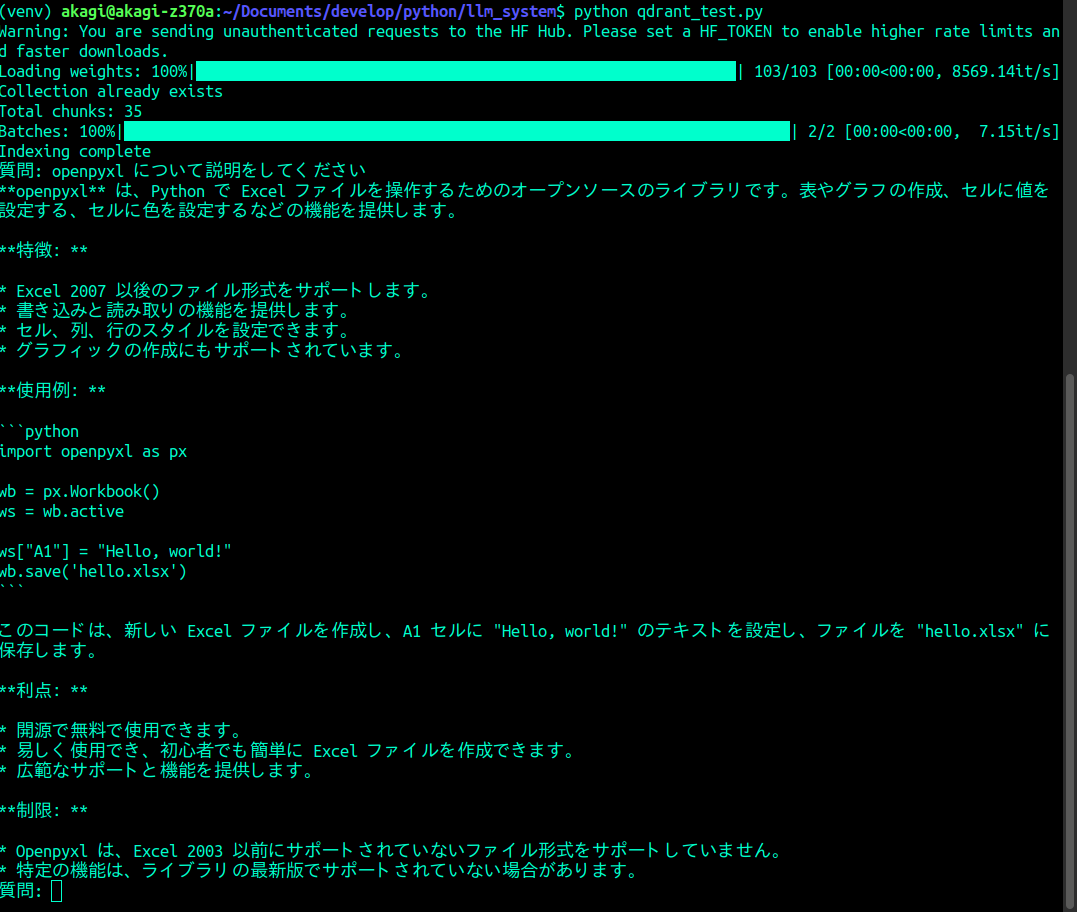
ほぼ実用に耐えるレベルの文章が生成されている。
が、ところどころ誤字と思われる箇所が見られる。
チャンクする文字列長などを考慮するなどが必要と思われる。
【補足】Gemma3:12B で再度動かしてみた。
どうやらGemmaにはGemmaとGemma2、そしてGemma3があるようだ。
アーキテクチャが根本から作り変えられており、無印のGemmaよりも日本語やコーディング能力等が向上しているようだ。
そこで、早速Gemma3:12Bを動かしてみた。まずはDL。8.1GBもあるので、ストレージ残量には注意。パラメータは12Billionなので120億ある。
ollama pull gemma3:12b
先のコードでgemma3:12bを呼び出すように書き換え、実行してみた。
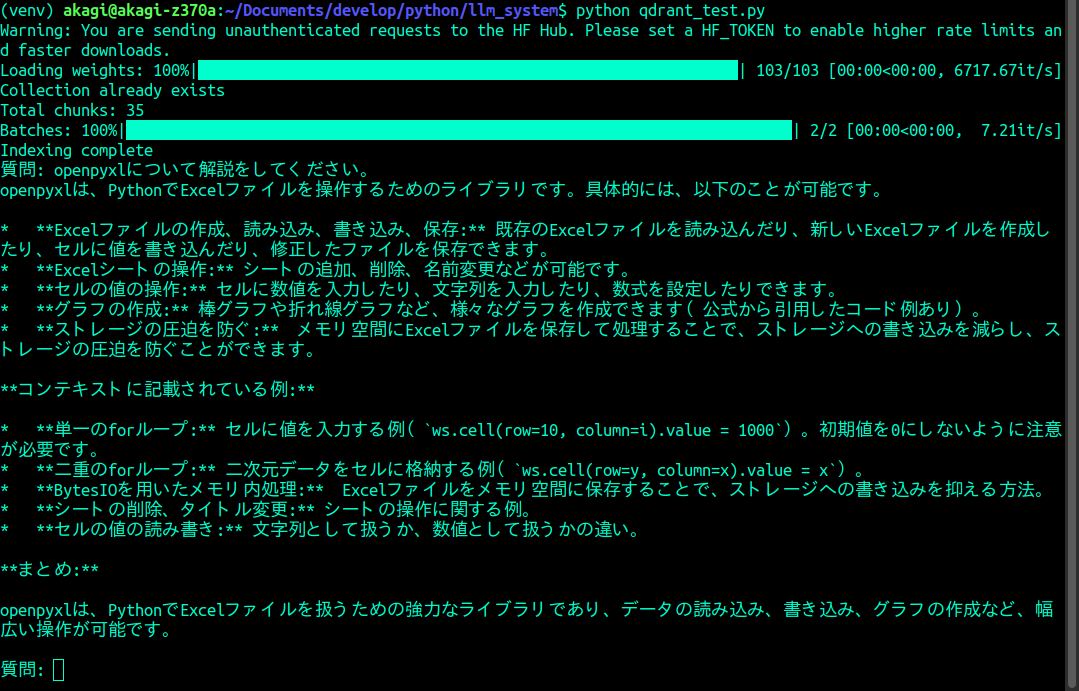
文章の密度が段違いである。コードの添付は無いが、かなり詳しい解説を提供してくれたようだ。
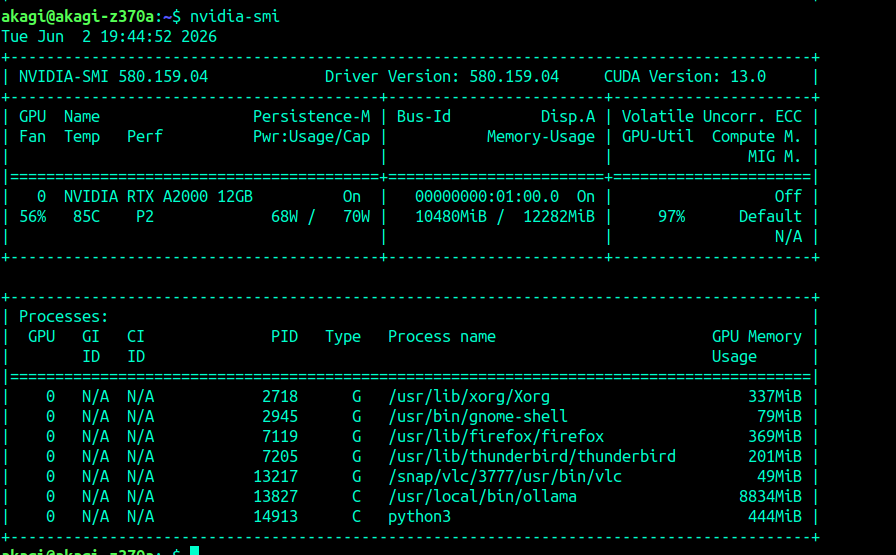
とはいえGPUの酷使が凄まじい。
もっと質問をしてみた。
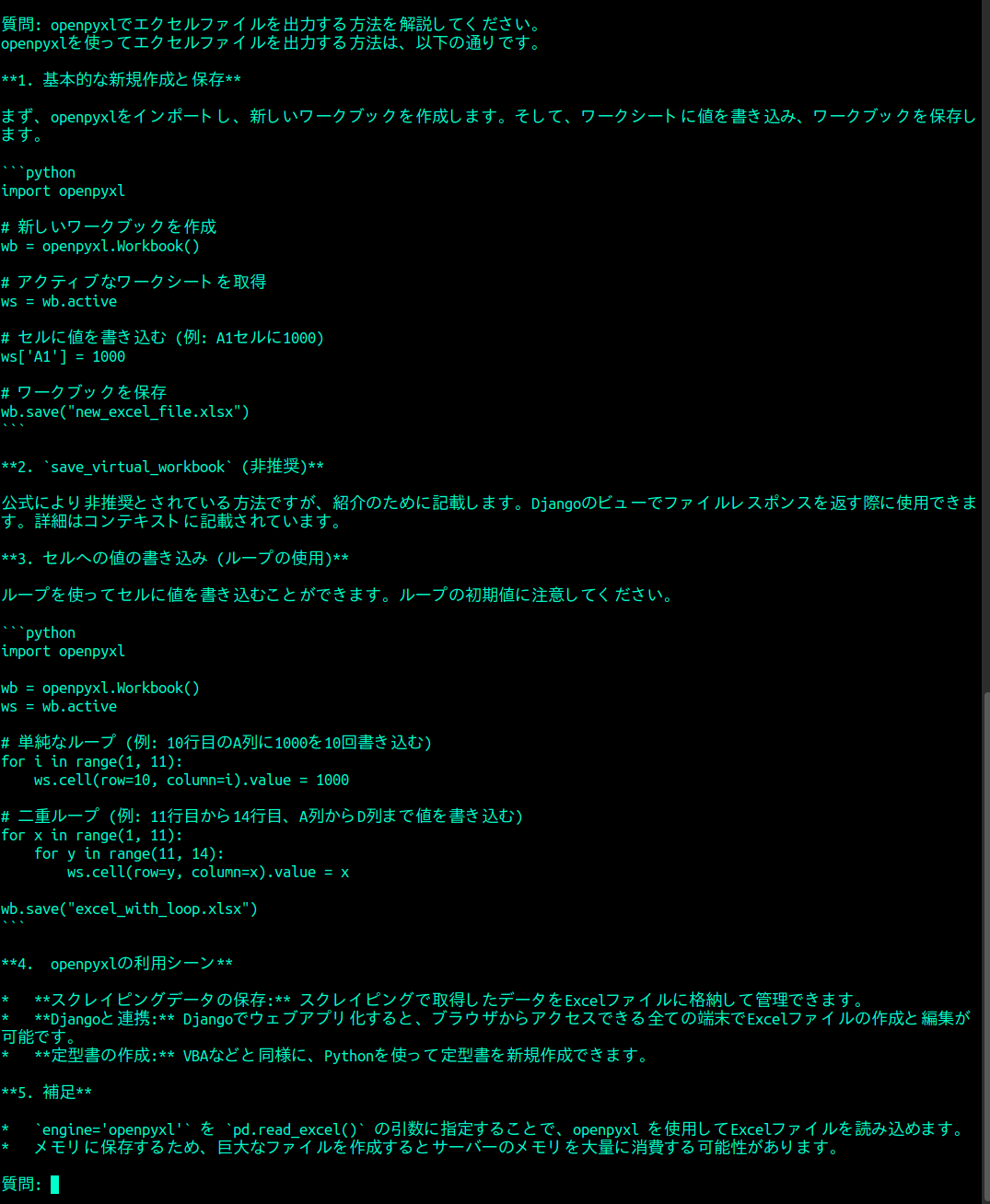
この長文も、生成時間は1分ほどとまだまだ許容できるレベルの待ち時間だ。これは、かなり使えるかもしれない。
私の拙い文章を与えるのではなく、文献の質と量を確保し、チャンクや近傍も調整して、他のパラメータも調整すれば、一昔前のChatGPTよりも遥かに良いものができるかもしれない。