AI実装検定A級のメモ

AI概論
AIのコンペ(ILSVRC)とAIの歴史
ILSVRC という画像認識の精度を競い合うコンペがあり、2012年の大会でディープラーニングが有用であると認識されるようになった。
2011年付近まではサポートベクターマシン(SVM)という手法が上位であったが、2012年にはAlexNetという手法が登場。これが従来のニューラルネットワークを元にして作られた、深層ニューラルネットワーク、ディープラーニングである。
ディープラーニングの強みは、特徴量の自動抽出にある。
通常の機械学習は特徴量を自分で設定しなければならない。
例えば、ガンのレントゲン写真であれば、ガンと認識できる箇所を自分で取得して、数値化し指定をする必要がある。
しかし、ディープラーニングはその必要がない。
ガンのレントゲン写真と、そうでないレントゲン写真の2種類を用意して、学習させるだけである。
特徴量の抽出は自動的に行われるため、データさえ得られれば高い精度が得られる。
- サポートベクターマシン: 機械学習の一種。回帰・分類問題に使われる。特徴量は手動で指定しないといけない。
- AlexNet: ディープラーニング(深層学習)の一種。特徴量を自動的に抽出できる。
つまり、機械学習は手動で照準を合わせる対空砲、深層学習は自動的に照準が合う対空ミサイルのようなもの。
このAlexNetの登場以降、深層学習を元にしたモデルが次々と登場。
- 2013年1位: ZFNet
- 2014年1位: GoogLeNet
- 2014年2位: VGGNet
- 2015年1位: ResNet
- 2016年1位: ensembled networks
- 2017年1位: SENet
エラー率は年々軽減され、2017年のSENetは0.023 、人間のエラー率の0.051 よりも遥かに優秀な結果が得られている。
少なくとも画像分類の分野においては、AIのほうが優秀な結果を出すことができるようだ。もっとも、AIに学習させるデータの質にも依存はするため、一概に優秀であるとは言えない。
ちなみに、先のAIモデルの特徴をまとめると以下のようになる。
| モデル名 | 登場年 | 主な特徴 |
|---|---|---|
| AlexNet | 2012 | ReLUを初めて大規模に導入し、GPUで高速学習。従来の手法に比べて圧倒的に高精度。 |
| ZFNet | 2013 | AlexNetを改良し、畳み込み層のフィルタサイズやストライドを最適化して性能向上。 |
| GoogLeNet | 2014 | Inceptionモジュールを導入し、パラメータ数を抑えながら高精度を実現。深さ22層。 |
| VGGNet | 2014 | 同一サイズの3x3畳み込み層を繰り返し使うシンプル構造。非常に深いが構造は単純で実装しやすい。 |
| ResNet | 2015 | 残差接続(skip connection)を導入し、非常に深いネットワーク(100層以上)でも学習が安定。 |
| Ensembling | 2016 | 複数のモデルを組み合わせて性能をさらに向上。個々のモデルはResNet系が多い。 |
| SENet | 2017 | チャンネルごとの重要度(Squeeze-and-Excitation)を学習し、より高い認識精度を実現。 |
また、優勝はしていないものの、以下のAIモデルは比較的有名なので、覚えておくとよいだろう。
- 2017年: DenseNet 特徴の再利用
- 2017年: MobileNet モバイル向け
- 2019年: EfficientNet 複合スケーリングによる精度と効率性の両立
ニューラルネットワークの学習の全体像
以下の手順でニューラルネットワークは学習されている。
- データの前処理
- 標本化・量子化(※主にアナログ信号→デジタル画像などの場合)
- 正規化、ベクトル化などをして入力データ(特徴量)を数値化する
- ニューラルネットワークへの入力
- 各層(入力層→隠れ層→出力層)で重みとバイアスを使った線形変換を行う
- その後、活性化関数を通して非線形性を加え、モデルの 表現力(学習できるパターンの多様性) を高める
- 例: ReLU, Sigmoid, Tanh など
- 出力層では、分類ならSoftmaxなどを使い確率に変換
- 損失関数で誤差の定量化
- モデルの出力(予測)と正解ラベルの誤差を計算
- 例:クロスエントロピー(分類)、MSE(回帰)
- モデルの出力(予測)と正解ラベルの誤差を計算
- 勾配降下法によるパラメータ更新
- 損失関数を最小にするよう、誤差逆伝播法を通じて重みやバイアスを少しずつ更新
この2〜4の間でニューラルネットワークは学習をしている。更にまとめると以下のようになる。
- データを入力して出力を得る(順伝播)
- 出力と正解を比べて損失値を出す(損失関数)
- 誤差を逆流させて、どこをどう直すか計算する(誤差逆伝播)
- 勾配降下法でパラメータを少し更新する(学習)
この学習を繰り返すことで、より洗練された学習モデルが作られる。
教師なし学習と教師あり学習
- 教師あり学習: 入力データと正解ラベルのセットを使って学習する(※犬・猫の画像をそれぞれ、犬、猫とつけたラベルのことを正解ラベルという)
- 教師なし学習: 正解ラベルがないデータの集まりで学習をする(似た画像同士でグループ分け(クラスタリング)をする必要がある)
代表的な教師あり学習
- 決定木 (ラベルをもとに分類)
- サポートベクターマシン(マージン最大化による分類)
- 線形回帰(回帰モデル)
代表的な教師なし学習
- k-means(クラスタリング、似たデータを自動でグループ化)
- 例1: 購買行動が似たものをグループ化(クラスタリング)して、DMを送るなど
- 例2: SNSの履歴から、興味のあるものをグループ化(クラスタリング)して、リコメンドの表示をするなど
参考: 【教師なし学習】k-means(k平均法)により似たデータをクラスタリング(グループ化)する
回帰問題と分類問題
- 回帰問題: 数値を予測する問題(不動産の情報から価格を予測する、気温を予測するなど)
- 分類問題: カテゴリを予測する問題(犬猫の分類、メールがスパムかそうでないかなど)
1. データの前処理関係
特徴量とは
特徴量とは、物体が物体であると認識できるもののことを言う。
例えば、犬の画像をAIが犬と認識するには、「耳が尖っている」「四足歩行である」「体毛に覆われている」などを特徴量と言い、それを認識している必要がある。
標本化と量子化
- 標本化: 一定間隔でサンプルリングし、ピクセル単位に分解すること
- 量子化: 各ピクセルの色の強さを、有限の数値に変換する処理
まず、標本化で、一定間隔で区切って分解をする。
続いて、量子化で、色の強さを0~255に丸める。
この標本化と量子化が画像認識において必須の前処理という作業。
標本化 → 量子化 → 入力データ作成 という工程を経て、モデルにデータを与え判定をすることができる。
2. ニューラルネットワークへの入力
前処理によって作られたデータを入力する。
データは層を経由して、重みとバイアスを使った線形変換(数式による表現)される。この数式こそがAIの学習モデルである。
このAIの学習モデル(数式)の表現力を更に高めるために、活性化関数を使う。
活性化関数の種類
ランプ関数(ReLU(Rectified Liner Unit))
0以上の値はそのままに、0以下の値をすべて0として扱う関数。
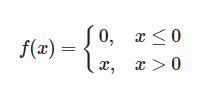
ニューロンへの入力が常に負の数になる場合、勾配が0になってしまい学習が進まなくなることがある。これをdying ReLU問題という。
- 参照元1: https://appswingby.com/relu%E9%96%A2%E6%95%B0-%E4%BB%8A%E6%9B%B4%E8%81%9E%E3%81%91%E3%81%AA%E3%81%84it%E7%94%A8%E8%AA%9E%E9%9B%86/
- 参照元2: https://mathlandscape.com/relu/
シグモイド関数(Sigmoid)
0より下は全部0.5未満になる。
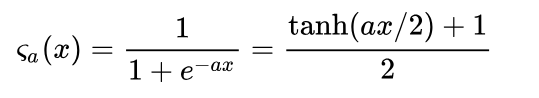
- 参照元1: https://ja.wikipedia.org/wiki/%E3%82%B7%E3%82%B0%E3%83%A2%E3%82%A4%E3%83%89%E9%96%A2%E6%95%B0
- 参照元2: https://atmarkit.itmedia.co.jp/ait/articles/2003/04/news021.html
Tanh
シグモイド関数の一種
ソフトマックス関数(Softmax)
バイアス項とは?
バイアス項とは、出力をずらすための定数項
例えば、y= Wx+b という重みつき入力Wxに対して、bというバイアスを与えて出力値をずらす。
y = Wx だけであれば、Wの値で傾きが変わるだけ。bがあれば表現できる範囲が広がる。
3. 損失関数で誤差の定量化
予測と正解の誤差がどれぐらいであるかを定量化(数値で表現)するため、損失関数を使う。
損失関数の種類
損失関数はAIの予測と正解との誤差(損失)を表現した値のことである。
この損失関数を使うことで、AIの予測がどれぐらい間違っているかが把握できる。
平均二乗誤差(MSE)
- 回帰問題向け
- 小さな誤差に対して有効
- ケアレスミスに対して強いが、大まかな理解には弱いイメージ
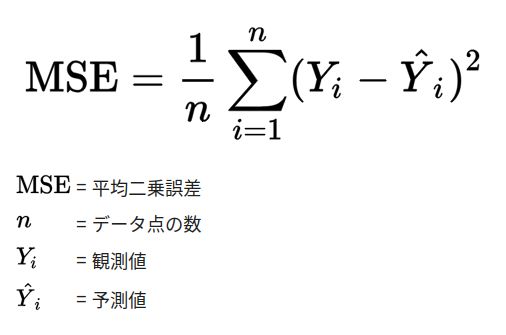
平均絶対誤差(MAE)
- 回帰問題向け
- 大きな誤差に対して有効
- 大まかな理解に対して強いが、ケアレスミスには弱いイメージ
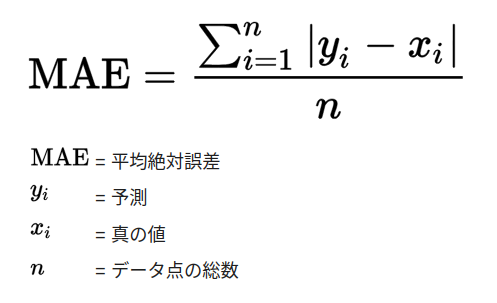
ハブ損失(Huber Loss)
- 回帰問題向け
- MSE,MAEをもとにして作られている
- 小さな誤差にはMSEを使い、大きな誤差にはMAEを使うことで、安定した学習ができる。

クロスエントロピー誤差
- 分類問題向け
- 二値分類、多クラス分類にも使える
- 確率分布をもとにした誤差、予測確率と実際のラベルとの差を測る
ハンジング誤差
- 分類問題向け
- サポートベクターマシン(SVM)で使う
- 分類境界からの距離を評価、線形分類に強い
Kullback-Leibler Divergence (KLダイバージェンス)
- 分類問題向け
- 確率分布比較で使う
- 2つの確率分布間の差を測定、生成モデルやベイズ推定に使用
スムースクロスエントロピー誤差 (Smooth Cross-Entropy)
- 分類問題向け
- 二値分類、多クラス分類にも使える
- クラス不均衡にも対応できる。
多クラス分類で、一部クラスのデータが少ないとき、クロスエントロピーで対処しきれない。
そこでクロスエントロピーをもとに改良し、クラス不均衡にも対応した。
ソフトマックスクロスエントロピー誤差 (Softmax Cross-Entropy Loss)
- 分類問題向け
- 多クラス分類に有効
- ソフトマックスによる確率分布を基にして誤差を計算できる
ソフトマックスとは、各クラスの出力値を確率に変換。その確率が合わせて1になるようにしたもの。
4. 勾配降下法によるパラメータ更新
損失関数によって損失(誤差)を求めた後、
- 誤差逆伝播法で勾配を求める(どの重みを調整したら損失が減るか調べる)
- 勾配降下法で、勾配を使って重みの更新をする(最適化)
このようにして、パラメータの更新を行う。
誤差逆伝播法(バックプロパゲーション)
ニューラルネットワークにおいて、出力と正解の誤差(損失)を、連鎖律(Chain Rule)を用い、ネットワークを逆方向に伝播させて計算をする手法
これにより、「どの重みをどれだけ変更すれば損失が減るか」がわかる。
得られた結果を元に勾配降下法を実行する。
勾配降下法
誤差逆伝播法で得られた勾配を元に、損失が小さくなるように各パラメータを更新する。
これが勾配降下法であり、この作業によりAIモデルは最適化される。
指標
学習モデルを使ってテストを行った結果、指標というものが得られる。
学習モデルがどれだけの精度であったかを見極める材料である。
- Accuracy(正解率) : 全ての予測中、正しく予測できた割合
- Precision(適合率) : 正解と予測したうち、実際に正解だった割合 ( 計算式: TP / (TP+FP) )
- Recall(再現率) : 実際に正解のうち、正解と予測できた割合 ( 計算式: TP / (TP+FN) )
- F1スコア: 適合率と再現率の調和平均
以上計算式は
- TP: True Positive
- TN: True Nagative
- FP: False Positive
- FN: False Nagative
Positiveは 正と予測した場合。Nagativeは負と予測した場合。
Trueは予測が正しかった場合。Falseは予測が間違っていた場合。
適合率と正解率の違い
適合率は、正解と予測したうち、実際に正解だった割合のことをいう。
例えば、ガンのレントゲン写真からガンとガンではないの2値分類をするとき。
- ガンであると予測した総数120枚(うち、実際にガンだったレントゲンは100枚)
- ガンではないと予測した総数50枚(うち、実際にガンではなかったレントゲンは40枚)
この場合、
- 適合率は 100枚 / 120枚
- 正解率は 140枚 / 170枚
である。
適合率と再現率の違い
一方、再現率は、
TP / (TP+FN)
この計算式によって求められる。
つまり、実際にガンだったのデータのうち、正しくガンであると予測できた割合のことをいう。
よって
100 / (100+10)
ガンではないと予測した総数は50枚。そのうち実際にガンではなかったのは40枚。
と言うことは10枚分は、本来はガンであるにも関わらず、ガンではないと判断された物。つまりFalse Nagative。
よって、再現率は以上の計算式になる。
F1スコアについて
F1スコアは適合率と再現率の調和平均である。適合率、再現率ばかり重視していると、
- 適合率だけ高い : 検出漏れが多い
- 再現率だけ高い : 誤検出が多い
ガンの話に例えると、
- 適合率だけ高い : 本来はガンなのに見逃される
- 再現率だけ高い : ガンではないのにガンとされ、ガン治療が施される
という状況になってしまう。ガンを見逃されるのも、ガンではないのにガンとされてしまうのも問題。
そこで、F1スコアを活用する。
F1スコア = (2 * 適合率 * 再現率) / (適合率 + 再現率)
となる。このF1スコアが高ければ、より的確にガンであると判断できると言える。
Q: 結局の所、正解率さえ高ければ良いのでは?
A: 正解率さえ高ければ良いという問題ではない。
仮に、正解率が高かったとしても、
- 適合率だけ高くて、ガンを見逃すAIモデル
- 再現率だけ高くて、ガンを誤検知するAIモデル
が生み出されてしまっては仕方ない。
更に、学習やテストに使われているデータが
- ガンのデータ5枚
- ガンではないデータ95枚
で、全部ガンではないと判定して95%の正解率だったとしても、それは使い物にならないだろう。
現場ではガンのデータも出てくる。それらも見逃してしまうようでは、役に立たない。
だから、正解率さえ高ければ良いというのは間違いである。
正解率はわかりやすい指標ではあるが、それで役に立つかは別問題である。
F1スコアは適合率と再現率の双方を考慮した値のため、どちらかと言えば、単に正解率だけ見るより、F1スコアを見ておいたほうが良いだろう。
参照元: https://zero2one.jp/ai-word/accuracy-precision-recall-f-measure/
数学
公式一覧
微分の基本公式

合成関数の微分
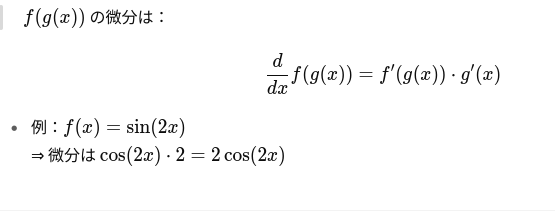
極限の基本公式
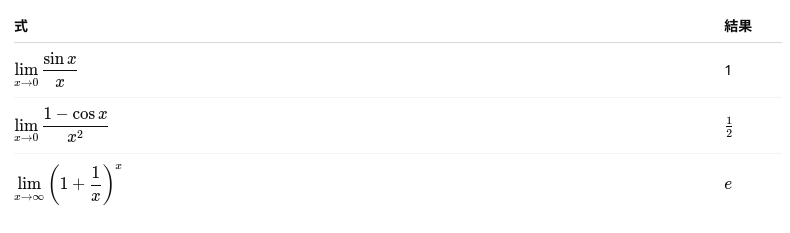
指数・対数の公式
勾配降下法

勾配降下法とは損失を小さくなる方向に少しずつパラメータを調整していく方法。
損失関数とはAIの予測と正解とのズレ(誤差)を数値で表現したもの。この損失関数を最小にすることがAI開発の目標である
- 損失: 誤判定
- 損失関数: 損失(誤判定)を数値化したもの
- 勾配降下法: 損失(誤判定)を最小にするために使うもの
ベクトル・ノルムの基本
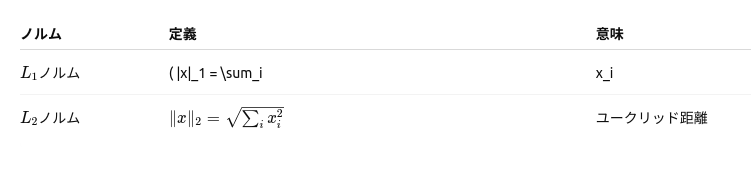
ベクトル
向きと大きさを持つ物。例えば(3, 4)というベクトルは、原点から横に3,縦に4進むという意味がある。この2つの要素があるベクトルを2次元ベクトルという。
1x4で4つの要素を持つベクトルを、4次元ベクトルという。
このベクトルは行列の一種である。(横、縦に長い行列。)
ノルム
ノルムはベクトルの長さを表現したもの。
L2ノルム(ユークリッド距離)はピタゴラスの定理(a^2 + b^2 = c^2)で求めることができる。
例えば (3, 4)であれば、
このように求めることができる。
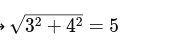
L1ノルム(タクシー距離)は、縦横にしか移動できない場合の移動距離の合計
(3,4)であれば、縦方向に4、横方向に3なので、足して7となる。
単にノルムとだけ書かれていた場合、一般的にはL2ノルムを意味している。
二次関数の最小値
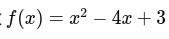
例えば、この最小値を求めるとき、平方完成を使うことで求めることができる。
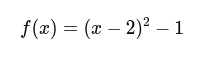
よって、答えは-1である。
行列
行列の形は (2 x 3)などと表現される。この場合。行が2行、列が3列となる。
行列の内積では、例えばA*Bのとき、Aの列数とBの行数が一致しなければ計算できない。
そのため、Bは(3 x X) などと3行である必要がある。
Aの列数とBの行数が 一致していることと、内積によって作られる行列の形は
A(m,n) B(n,p)
AB = (m,p)
このサイズが得られる。つまり、2x3 行列と 3x7 行列の場合、2x7行列が得られる。(左側の行数, 右側の列数)
内積
例えば、AxBのとき、
Aが
[1, 1]
[3, 5]
Bが
[4, 7]
[2, 4]
AxBは以下のようになる。
[
(1×4 + 1×2), (1×7 + 1×4) → 6, 11
(3×4 + 5×2), (3×7 + 5×4) → 22, 41
]
Aの行に、Bの列を掛ける。
外積(クロス積)
外積は ベクトル同士の掛け算であり、新しいベクトルをつくることができる。
u = [[1],
[2],
[3]]
v = [4, 5]
outer product u ⊗ v =
[
[1×4, 1×5],
[2×4, 2×5],
[3×4, 3×5]
] =
[
[4, 5],
[8, 10],
[12, 15]
]
つまり、新しく3x2行列をつくることができる。
内積と外積の違い
内積は、通常の行列の掛け算。
AxBの場合 Aの列数とBの行数が一致しなければ計算はできない。
内積の主な用途は、
- 線形変換
- ニューラルネットの伝播
などがある。
一方、外積は次元が揃っていなくても計算はできる。
外積の主な用途は、
- ニューラルネットの勾配計算
- 特徴抽出
などがある。
アダマール積
アダマール積は内積や外積と違い、行列の各要素を掛け算していく。
そのため、行数も列数も一致していなければ計算はできない。
アダマール積の主な用途は、
- マスク処理
- ゲート・注意機構
- 画像同士の演算
- フィルタ処理
などがある。
単位行列と逆行列
単位行列は
I = [
1 0
0 1
]
このような対角線上の成分がすべて1という行列。EやIなどと表現されることがある。(EinheitのE,Identity ElementのI)
AxI もしくはIxA でもAが得られる。
逆行列に関して、
A = [
a b
c d
]
- 正方行列(3x3 や5x5などの行数と列数が同じ)
- 行列式(ad-bc)が0でない(特異行列(singular matrix)ではない)
に限り、逆行列 det(A) は
A⁻¹ = (1 / (ad - bc)) × [
d -b
-c a
]
このように表現をする。det は デターミナント(determinant)のdetである。
aとdを逆転、bとcをマイナスにする。
3x3以上の逆行列は以下を参照。複雑なので、アプリやライブラリを活用することのほうが多い。
https://keisan.casio.jp/exec/system/1278758277
numpyを使う方法も有効。
import numpy as np
A = np.array([
[1, 2, 3],
[0, 1, 4],
[5, 6, 0]
])
A_inv = np.linalg.inv(A)
print(A_inv)
固有値と固有ベクトル
Python
試験範囲には
- numpy
- pandas
- matplotlib
- seaborn
- scikit-learn
この5つのライブラリが含まれる。
対策に有効と思われる書籍
numpy
pip install numpy
numpy は数値計算を効率的に行うことができる。
Cを元に作られているので、numpyの計算時にはPythonのGILの影響を受けず高速処理が可能である。
サンプルコード
import numpy as np
print("#===== 配列(行列)の生成 =====#")
# 配列をつくる。
x = np.array([1,2,3,4,5])
print(x)
# ↑ と↓は等価。arange は range関数と同じような仕組み。
x = np.arange(1,6)
print(x)
# 0〜9までの値で配列をつくる
x = np.arange(10)
print(x)
# 0から100までの偶数の配列をつくる。
x = np.arange(0,101,2)
print(x)
# 要素数に合わせて、形状を変更する。10個の要素なので、2x5行列に変換。
x = np.arange(10)
x = x.reshape((2,5))
print(x)
# 更に形状を変える。
x = x.reshape((5,2))
print(x)
# 行列から1次元配列にも戻せる。
x = x.reshape((10))
print(x)
# 要素数が一致していない場合は例外。
"""
x = x.reshape((3,3))
print(x)
"""
# 要素が5つある配列をつくる。値は0~9までのランダム
x = np.random.randint(10, size=(5))
print(x)
# 3x5の行列をつくる。値は0~9までのランダム
x = np.random.randint(10, size=(3,5))
print(x)
# ゼロ埋めして、行列をつくる。 dtype で型指定。
x1 = np.zeros(5, dtype=np.float16)
x2 = np.zeros((5,6), dtype=np.float32)
x3 = np.zeros((2,3,4), dtype=np.uint8)
"""
# TIPS : dtype の型指定は Pythonの標準型(float, int など)でも可、自動変換される。 np.bool_ などブーリアン型もある。
# 参照: https://kentei.ai/blog/archives/726
"""
print( x1 )
print( x2 )
print( x3 )
print("#===== 行列(配列)の抽出・連結・比較 =====#")
A = np.random.randint(10, size=(4,5) )
B = np.random.randint(10, size=(4,2) )
C = np.random.randint(10, size=(2,5) )
print( A )
print( B )
print( C )
# array[start_row:end_row, start_col:end_col] 行列の抽出ができる
# 左上から2x3 の行列を抽出する。
print( A[:2,:3] )
# 行列の連結
# axis が 0 縦方向(行方向)に結合 (列数が一致していないと例外)
# axis が 1 横方向(列方向)に結合 (行数が一致していないと例外)
print( np.concatenate([A, C], axis=0) )
print( np.concatenate([A, B], axis=1) )
# 行列内の要素の比較 最小値、最大値を取り出す。
print( A.max() )
print( A.min() )
print("#===== 配列計算 =====#")
# [0,1,2,3,4] の配列をつくる
x = np.arange(5)
print(x)
# 各配列の要素に3を足す。
print(x+3)
# 2を引く
print(x-2)
# 5を掛ける
print(x*5)
# 2で割る
print(x/2)
# 2で割った整数部(小数切り捨て)
print(x//2)
# 2で割ったあまり
print(x%2)
# 4乗する
print(x**4)
print("#===== 行列計算 =====#")
# 2次元配列で行列計算
A = np.array([
[1,2,],
[3,4,],
])
B = np.array([
[1,2,3,],
[3,4,5,],
])
C = np.array([
[3,6, ],
[2,7, ],
])
# 行列の形状を調べる(タプル型)
print( A.shape )
print( B.shape )
# 次元数の表示
print( A.ndim )
print( B.ndim )
# 要素数の表示
print( A.size )
print( B.size )
# ABの内積 ( ※Aの列数、Bの行数が一致していない場合ここで例外が出る。)
print( A.dot(B) )
# Python3.5以降では 内積は@を使って表現もできる
print( A@(B) )
# この表現でも可
print( A @ B )
# A B の外積(クロス積)
print( np.outer(A, B) )
# AとC のアダマール積
# アダマール積は 普通に掛け算すれば良い。行列の形が一致していなければ例外。
print( A*C )
# Aの逆行列
print( np.linalg.inv(A) )
# 行列式(ad - bc)が0の場合 の逆行列は例外
"""
x = np.array([
[ 1, 3 ],
[ 3, 9 ],
])
print( np.linalg.inv(x) )
"""
# 行列式(ad - bc)の計算
print( np.linalg.det(A) )
# 5次元の単位行列
print( np.eye(5) )
pandas
pip install pandas
pandas はデータフレームという構造を使って、表形式のデータを効率良く扱うことができる。
CSV,Excel,テキストファイルやSQLデータベースまで扱うことができる。
- (公式) https://pandas.pydata.org/
- (ドキュメント) https://pandas.pydata.org/docs/reference/index.html
- https://ja.wikipedia.org/wiki/Pandas
- https://pypi.org/project/pandas/
- 【データ分析】pandasの基本的な使い方、グラフ描画、ファイル読み書き、計算等【バックエンドにopenpyxlとmatplotlibを使う】
サンプルコード
このサンプルコードではタイタニック事件の乗客データが格納されているCSVを扱う。
- データ元: https://raw.githubusercontent.com/mwaskom/seaborn-data/master/titanic.csv
- データ元のGitHub: https://github.com/mwaskom/seaborn-data
データのラベルは以下の通り。
- survived: 生存したかどうか(0 = 死亡、1 = 生存)
- pclass: チケットのクラス(1 = 上級、2 = 中級、3 = 下級)
- sex: 性別(“male” = 男性、“female” = 女性)
- age: 年齢(欠損値あり)
- sibsp: 同乗していた兄弟・配偶者の数
- parch: 同乗していた親・子供の数
- fare: チケットの料金
- embarked: 乗船地(C = Cherbourg、Q = Queenstown、S = Southampton)
- class: pclass と同じ内容(文字列で “First”、“Second”、“Third”)
- who: 年齢と性別をもとにした分類(“man”、“woman”、“child”)
- adult_male: 成人男性かどうか(True / False)
- deck: デッキ(客室のある階層、A〜G。欠損値多め)
- embark_town: 乗船した港の名前(例: “Cherbourg”)
- alive: 生存したかどうか(“yes” / “no”)
- alone: 一人旅だったか(True = 一人、False = 家族などと同乗)
import pandas as pd
# CSVをデータフレームとして読み込みをする。
df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/titanic.csv" )
# ヘッダー(ラベル)を削除して読み込みする
df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/titanic.csv", header=0 )
print(df)
# 列ラベルの一覧を取り出す。(index型オブジェクト、そのままforループできる)
print(df.columns)
# list 関数を使うことで配列として使える
print(list(df.columns))
# 行ラベルの一覧を取り出す
print(df.index)
print(list(df.index))
# 各データのデータ型を調べる。
print(df.dtypes)
"""
[891 rows x 15 columns]
survived int64
pclass int64
sex object
age float64
sibsp int64
parch int64
fare float64
embarked object
class object
who object
adult_male bool
deck object
embark_town object
alive object
alone bool
dtype: object
"""
print("======= 列ごとに値の確認とカウント、値の変換 ===========")
# alive の yesとnoを TrueとFalseに変換する。ただし、値の種類は本当にyesとnoだけなのか調べる。
# 特定列の値の種類を表示(重複は除去)
print(df["alive"].unique())
# 特定列の値ごとに出現数をカウントする。NaNも含める。
print(df["alive"].value_counts(dropna=False))
# noとyes は TrueとFalseに変換する(元のaliveを上書きする。)
df["alive"] = df["alive"].map({"yes": True, "no": False})
print(df)
print("======= NaNを含んだデータを除去する ===========")
# 年齢がNaNになっているデータを削除、inplace=True で元データに上書きする。
df.dropna(subset=["age"], inplace=True)
# 客室のある階層がNaNのデータも削除
#df.dropna(subset=["deck"], inplace=True)
# 全列で 1つでもNaNが含まれる行を削除する。
#df.dropna(inplace=True)
print(df)
# 列ごと削除する。
df.drop("deck", axis=1 , inplace=True)
# 行ごと削除する(インデックス番号を指定する) (※欠番になってしまう。)
df.drop(3, axis=0, inplace=True)
# 欠番になっているデータのインデックスを連番にし直す。
df.reset_index(inplace=True)
print("======= ファイルの保存をする =========")
df.to_csv("test.csv")
seaborn
pip install seaborn
seabornはmatplotlib のラッパー系ライブラリ
pandasのデータフレームを直接扱え、短いコードでグラフを描画することができる。
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
print("男性と女性での生存率を調べる")
# x軸に性別、y軸に生存値(1なら生存、0なら死亡)とする。これで、棒グラフの平均を生成できる。
sns.barplot(data=df, x='sex', y='survived')
plt.title("Survival rates by Gender")
plt.show()
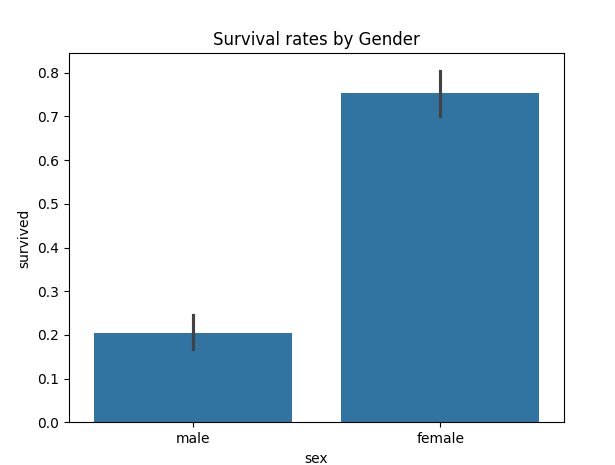
この通り、男性は20%に対して、女性は75%以上。
続いて、年齢別の生存率を確認する。
# 年齢ごとに区分けする。 0~12歳は子供、60歳までは大人、100歳までは高齢者
df['age_group'] = pd.cut(df['age'], bins=[0, 12, 60, 100], labels=['child', 'adult', 'elderly'])
sns.barplot(data=df, x='age_group', y='survived')
plt.title("Survival rates by Age")
plt.show()
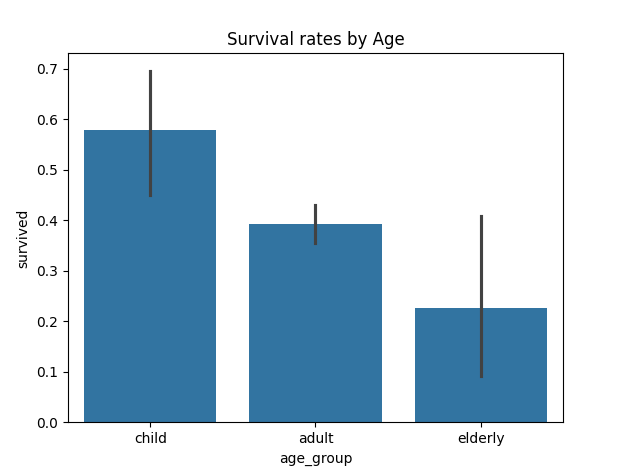
全体的に見れば、子供の生存率のほうが高いように見える。
では、年齢グループを更に男女で分け、かつ生存率ではなく生存者数で確認してみる。
# 積み上げ棒グラフ x軸は年齢グループ、更に性別ごとに分け、kind='count'として数をカウント。
sns.catplot(data=df, x='age_group', hue='sex', col='alive', kind='count')
plt.show()
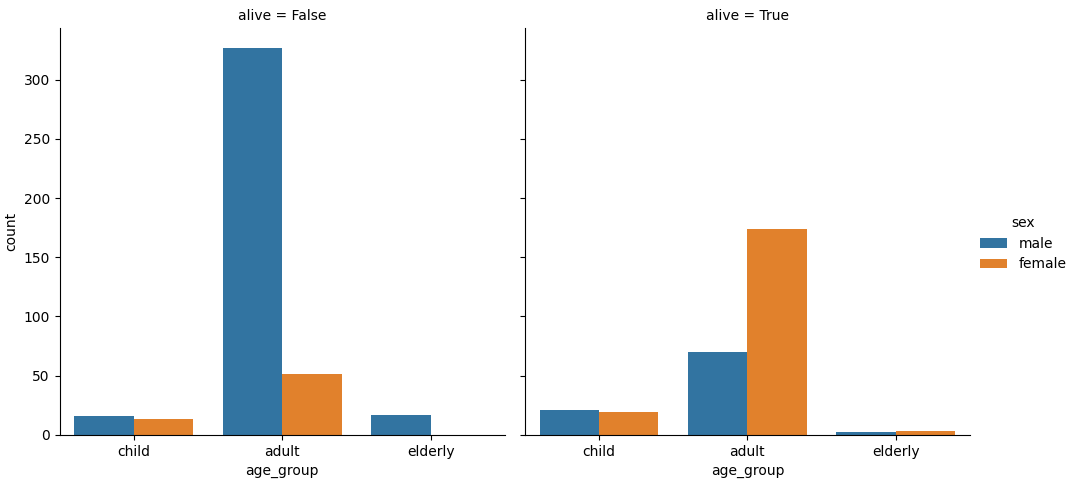
pivot = df.pivot_table(index='sex', columns='age_group', values='survived')
sns.heatmap(pivot, annot=True, cmap="YlGnBu")
plt.title("Survival Rate by Sex and Age Group")
plt.show()
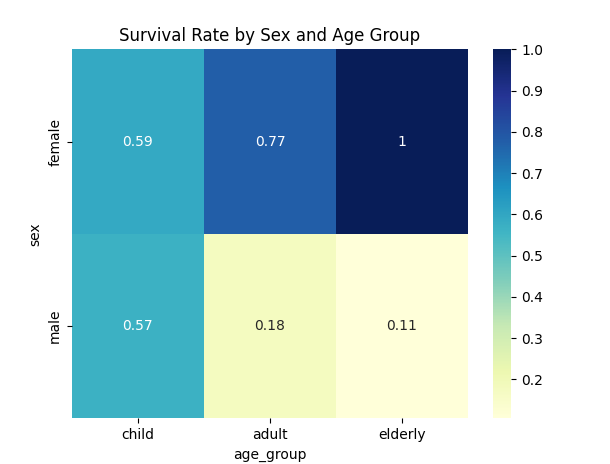
以上のグラフから、以下のことが言える。
- 子供の生存率が高いように見えるのは、大人の男性の死亡率が高いため、相対的に高く見えるだけ
- 高齢者はほとんど乗船していないし、ここでも男性の死亡率は高め、女性は生存率100%
- 子供は男女関係なく生存・死亡している
- 一番生存率が高いのは子供ではなく、大人の女性
matplotlib
pip install matplotlib
matplotlib はグラフ描画ができるライブラリ。numpy配列のデータに対応している。
日本語をグラフに表示させる場合は、別途フォントファイルを用意する必要がある。
- (公式) https://matplotlib.org/
- https://ja.wikipedia.org/wiki/Matplotlib
- https://pypi.org/project/matplotlib/
- 【matplotlib】フォントファイルを用意して日本語の豆腐化を修正する
scikit-learn
pip install scikit-learn
scikit-learnは機械学習を行うことができるライブラリ。
強化学習・深層学習などには対応していないものの、基本的な回帰・分類問題には対応可能。
- (公式) https://scikit-learn.org/stable/
- https://ja.wikipedia.org/wiki/Scikit-learn
- https://pypi.org/project/scikit-learn/